
As industry races for use cases of Large Language Models, software devs have emerged as early adopters. Can LLMs help us translate between tech and talk? Let’s build a text-to-SQL application with Vanna and Streamlit!
How many of us have struggled to communicate with non-technical audiences about data? So much of what we do as software engineers doesn’t translate to our users and our counterparts on the business side. If your customer wants to understand why their account has been flagged, they can’t query the database directly. Admittedly, that would be a bad idea for many reasons, but even if you were to give them readonly credentials, they’d have to write a valid query in order to answer their question. That’s pretty unlikely unless they somehow already know SQL!
Most applications include web-based user interfaces with drop-down menus which enable the customer to compose parameters for a valid query, which can then be executed on the back end. With the rise of Large Language Models (LLMs), many businesses are starting to wonder if it might be possible to streamline with simple chat interfaces, which use a text-to-SQL language model on the back end to translate between the natural language questions of the user to valid SQL queries that can be directly executed against the database.
In this post, we’ll explore the technical feasibility of such an approach.
Just here for the code? Check out this repo for the full example.
Getting Started
Vanna is an open source Python library developed by Vanna.AI. It uses Retrieval Augmented Generation (RAG), which is a technique that is used to improve the accuracy of LLMs. The idea is to provide data to an LLM that it was not previously trained on to ensure that it can generate reasonable responses to questions related to this data. In this case, the data provided is the knowledge about the internals of your database. The process will be covered later in this post.
Step 1: Create a free Vanna.AI account
Follow the instructions in the Vanna.AI website to create an account. Once you are logged in, you will need to do the following:
- Get an API key (click on
API Keyson the left side of the page) - Create a new RAG model (click on
RAG Modelson the left side of the page and choose a unique name for your model and click on theCreate Modelbutton)
Step 2: Create and activate a virtual environment
Run the following on the command line to create a fresh new Python virtual environment:
virtualenv venv
source venv/bin/activate
Step 3: Install the requirements
In order to run the code, the following Python libraries are required:
- streamlit
- vanna
- vanna[postgres]
pip install -r requirements.txt
Train the RAG model
The following is a code snippet of the DatabaseTrainer class:
from vanna.remote import VannaDefault
INFO_SCHEMA_QUERY = "SELECT * FROM INFORMATION_SCHEMA.COLUMNS"
class DatabaseTrainer:
"""
DatabaseTrainer uses Vanna AI to learn in the internals of a Postgres database
to enable users to use natural language to generate and execute SQL queries
"""
def __init__(self, api_key=None, model=None, db_creds=None):
"""
Parameters
----------
api_key : string
The API key used to connect to Vanna AI
model : string
The name of the model that will be trained; the model needs
to be set up in your Vanna AI account prior to use
db_creds : dict
Credentials to connect to a Postgres database. The dictionary
must contain the following keys: host, port, user, password, dbname
"""
if api_key is None or api_key == "":
raise ValueError("api_key must be a valid non-empty string")
if model is None or model == "":
raise ValueError("model must be valid non-empty string")
if db_creds is None:
raise ValueError("db_creds must be a valid non-empty dictionary")
# Initialize vanna
self.vn = self._init_vanna(api_key=api_key, model=model)
# Connect to the Postgres database
self._connect_db(db_creds)
def _init_vanna(self, api_key, model):
"""
Initialize the VannaDefault class by using the API key to connect to
the model set up in your Vanna AI account
"""
vn = VannaDefault(api_key=api_key, model=model)
return vn
def _connect_db(self, db_creds):
"""
Connect Vanna to the postgres database
"""
self.vn.connect_to_postgres(host=db_creds["host"], port=db_creds["port"], user=db_creds["user"], password=db_creds["password"], dbname=db_creds["dbname"])
def train(self, ddl=None):
"""
Train the model
Parameters
----------
ddl : string
"CREATE TABLE" SQL statements of the tables in your database.
"""
if ddl is None or ddl == "":
raise ValueError("ddl must be a valid non-empty string")
# query the information_schema to get the table and column information from the database
db_info_schema = self.vn.run_sql(INFO_SCHEMA_QUERY)
# break up the information schema into bite-sized chunks that will be referenced by the LLM
plan = self.vn.get_training_plan_generic(db_info_schema)
self.vn.train(plan=plan)
self.vn.train(ddl=ddl)
print("Training complete!")
Let’s break it down step by step.
To initialize the DatabaseTrainer, you need to pass in the following parameters:
api_key: Vanna API Keymodel: RAG model namedb_creds: Credentials to connect to your Postgres database (this is a dictionary with the following keys: host, port, user, password, dbname)
The __init__ method does the following:
- Initialize the
VannaDefaultclass by using the API key to connect to the model set up in your Vanna AI account. - Connect Vanna to your Postgres database using the database credentials.
The train method requires a ddl parameter. This parameter is a string that contains all the CREATE TABLE SQL statements of the tables in your database. This method does the following:
- Run the following query to retrieve the table and column information from the database:
SELECT * FROM INFORMATION_SCHEMA.COLUMNS. - Train the RAG model on the information schema and the ddl.
The following code snippet is an example of how you can execute the training process:
from src.database_trainer import DatabaseTrainer
database_trainer = DatabaseTrainer(api_key="Your Vanna API key",
model="Your Vanna RAG model",
db_creds="Your database credentials")
database_trainer.train(ddl="Your database DDL")
Run the Streamlit text-to-sql LLM application
Now that the RAG model has been trained, it’s time to integrate it into an application. Vanna has a few boilerplate examples on its website that you can use to get started. The code to run the application is based off Vanna’s streamlit example. You will need to add the following secrets in the .streamlit/secrets.toml file:
VANNA_API_KEY="Your Vanna API key"
MODEL="Your Vanna RAG model"
POSTGRES_HOST="Database host"
POSTGRES_PORT="Database port"
POSTGRES_USER="Database user"
POSTGRES_PWD="Database password"
POSTGRES_DB="Database name"
To run the application, simply run the following command:
python -m streamlit run sql_app.py
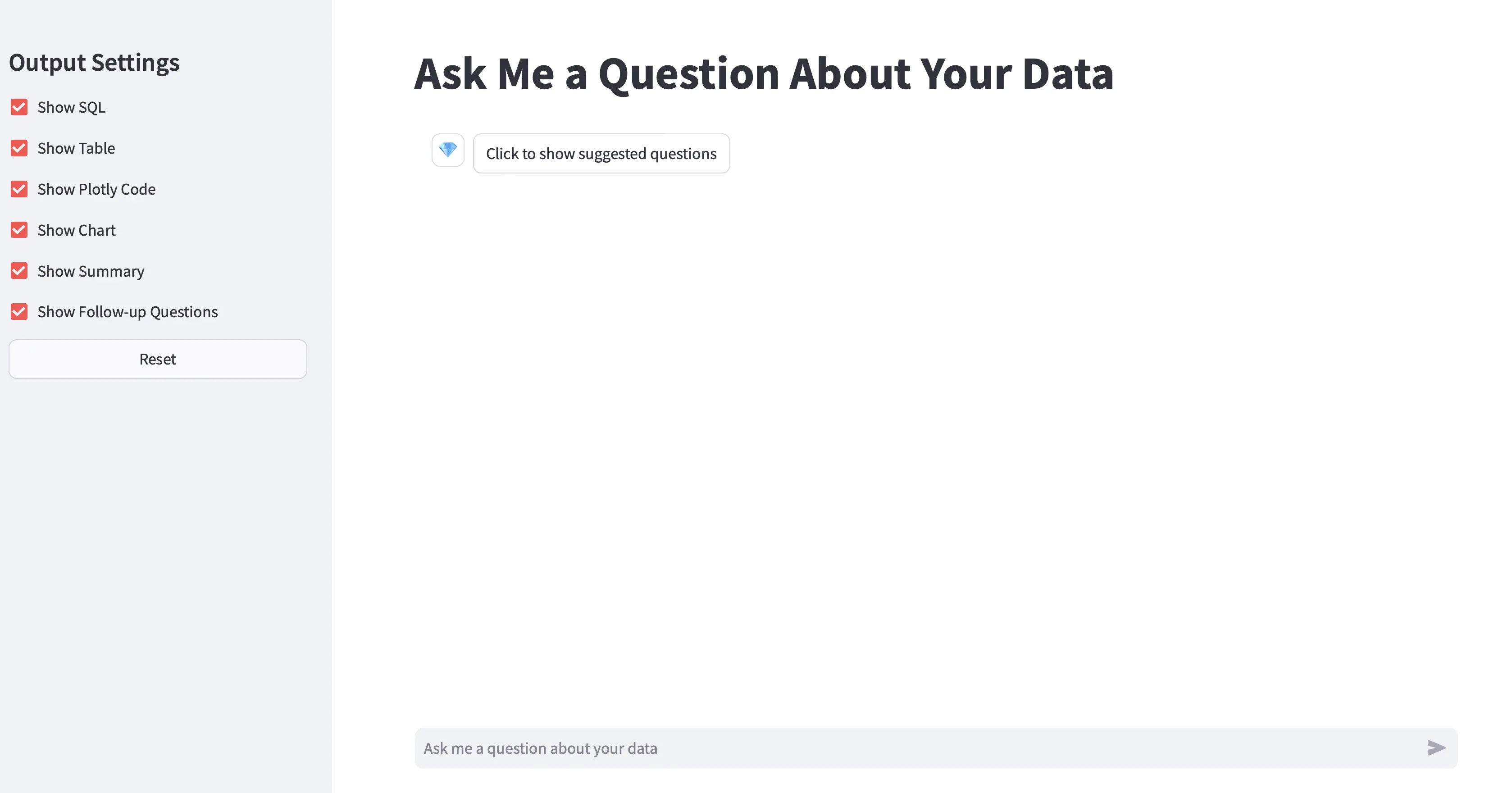
The following is a screenshot of the application. It provides the following functionality:
- View suggested questions
- Display and execute the SQL code
- See a table of the results
- If applicable, show and execute Plotly code and display a chart
- Show follow up questions
The repo includes a demo of the application.
Conclusion
As this post demonstrated, LLMs can be used to accelerate data analysis tasks by training a RAG model to build a text-to-sql application. This post just scratches the surface on how to build these types of applications.
Two important things to keep in mind…
Data Privacy
Vanna supports many databases including Postgres, SQLite, BigQuery, Snowflake, etc. You can start experimenting with a Jupyter Notebook or create applications using Streamlit, Flask, Slackbot, or integrate it within your own front end application. The pricing options are as follows:
- Open source: You use your own LLM, set up a local metadata storage using ChromaDB or any other vector database, and deploy via self-hosted Streamlit, Flask app, etc. You also have the ability to customize as you see fit.
- Free tier: This tier uses the GPT 3.5 foundational model, hosted metadata storage and rate-limited usage of the LLM. Note: This example uses the free tier plan for Vanna and a Postgres database.
- Paid tier: This tier costs $30/ 1 million tokens, uses the GPT-4 with a load-balanced fallback to other LLMs. It also provides SLA guarantees.
- Enterprise tier: Contact Vanna AI for a pricing plan that gives you access to developers who can help you customize your application based on your enterprise needs.
Depending on the sensitivity of the data in your database, carefully consider the above options when you are building the application. This particular example uses a hosted LLM solution, which means that the data will be sent externally to the LLM. If you do not want to share your internal data with Vanna, you have the option to use Vanna with your own custom LLM, vector database, and RAG process and host the application on your own server. Vanna AI provides documentation on how to set this up. More details about Vanna’s data security policy can be found here.
Accuracy
One of the major drawbacks of LLMs is their tendency to hallucinate and produce inaccurate results. According to the BIRD benchmark, the best performing text-to-SQL LLM in its leaderboard has an accuracy rate of 67.86%. The BIRD paper stated that in spite of advances in LLMs and creative use of prompt engineering, they still struggle to outperform human beings. On some level, it makes sense, foundation LLMs are trained on a broader data set and struggle to perform well on a niche use case such as converting text to SQL.
However, the paper also notes that “external knowledge evidence in BIRD is effective and instructive for models to better understand the database values”. In fact, the accuracy of one of the models in the tests it conducted went up from 34.88% to 54.89%. What this means is that providing the LLM with more knowledge and context about your database and the underlying data will help improve the quality of the text-to-SQL application. In fact, Vanna also published an article that demonstrates how it tested different LLMs and context strategies to maximize accuracy.
They recommend the following suggestions to reduce errors:
- Train the model on documentation about your tables. For example, you can describe the type of data the table holds and possible values for fields in those tables. The way to train on documentation is as follows:
vn.train(documentation="insert documentation here") - Train the model on commonly run SQL queries:
vn.train(sql="insert sql here") - Train the model on question-sql pairs:
vn.train(question="insert question here", sql="insert sql here")
Furthermore, the accuracy of the model can be improved over time by incorporating user feedback. For example, you can ask users to indicate whether a result was correct or not and have an input section where they can provide the correct answer. This feedback can be turned into new question-SQL pairs that can be used to train the model.
All of this highlights a salient point: using LLMs to completely automate data analysis tasks is not advisable. What we have seen in practice is that the best use case for LLM applications is to streamline a end user’s workflow, not to replace the workflow entirely with an automated solution. Think of these applications as intelligent agents or copilots rather than replacements.
Photo by Luke Chesser on Unsplash








