

If you’ve worked with generative AI models you know they can be fickle and sometimes fail to meet the expectations of users. How can we move towards models users trust and see clear value in? Let’s engineer a user-feedback loop!
Getting models in front of users
A prerequisite for gaining user trust is to grant model access to the actual intended users. This might feel obvious but it really should be done as early as possible in development. End users will often have very different expectations than developers and engineers. For example, a model that allows users to “chat with their data” could be interpreted in many different ways. Exposing models to users exposes fundamental communication and expectations issues that you would rather know about early on in the collaboration process.
Usually, this means setting up a test environment to validate the model in a user context. A side benefit of this is that it forces you to think about deployment at an early stage and answer logistical questions (e.g. What GPU resources do I need to run this model?). For text generation, TGI or text-generation-webui are powerful backends that can serve transformer-based models. In the case of text-generation-webui, you also get a full-fledged UI that’s targeted towards developers. If you just need a backend, TGI will get you there fairly quickly.
You can very easily build your own UI with streamlit or gradio. For chat-based applications I prefer gradio because there’s a very handy ChatInterface element you can use to implement a ChatGPT-style interaction. Here’s a basic gradio template that connects to a text generation server hosted by HuggingFace for real-time interactivity.
import gradio as gr
from huggingface_hub import AsyncInferenceClient
# Start the text generation client
client = AsyncInferenceClient("HuggingFaceH4/zephyr-7b-beta")
async def get_response(message, history):
"""
Stream the response from the model.
"""
# Invoke the inference API with the conversation history
messages = []
for user, assistant in history:
messages.append({"role": "user", "content": user})
messages.append({"role": "assistant", "content": assistant})
messages.append({"role": "user", "content": message})
stream = await client.chat_completion(
messages=messages, stream=True, max_tokens=64
)
# Stream the response to the UI - this emulates ChatGPT-like behavior
output = ""
async for chunk in stream:
output += chunk.choices[0].delta.content
yield output
# Configure the app
with gr.Blocks() as app:
chatbot = gr.Chatbot(render=False)
textbox = gr.Textbox(placeholder="Enter a message...", render=False)
clear = gr.Button("🗑️ Clear", render=False)
interface = gr.ChatInterface(
get_response,
chatbot=chatbot,
textbox=textbox,
retry_btn=None,
undo_btn=None,
clear_btn=clear,
)
app.launch()
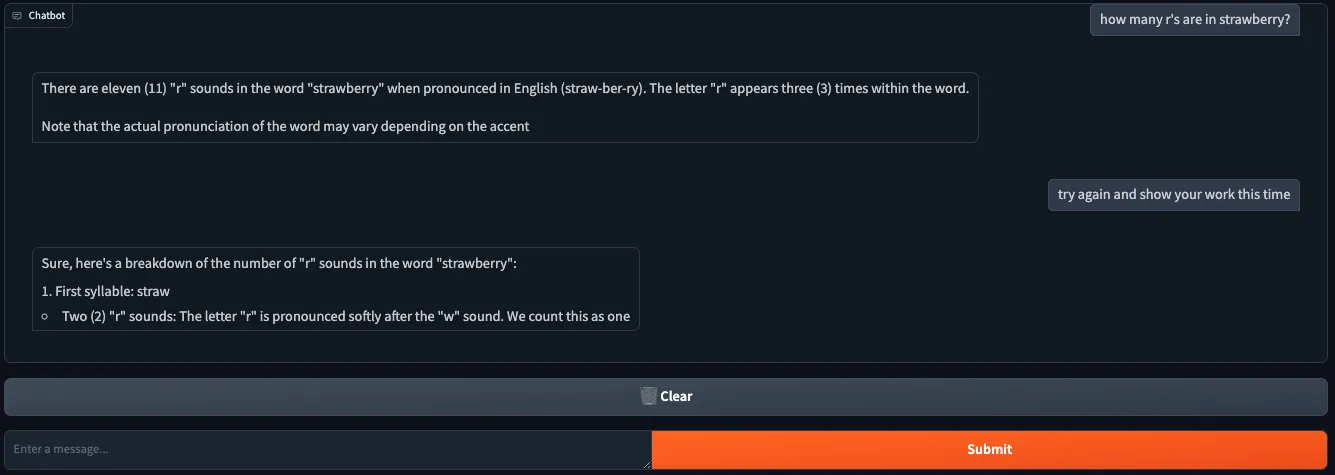
Collecting user feedback
Having a model that users and developers can interact with is a good first step. It can make obvious which features or aspects of the model are not working and helps set expectations more accurately.
However, most tech teams struggle when it comes to gathering real-time user feedback. If our model is trained for a specific domain, only our end users know if the responses are actually helpful or correct. It’s not enough for us as engineers to say, “the response looks human so it’s probably okay”.
Since gradio apps are defined functionally it’s fairly straightforward to add instrumentation code to capture human feedback. If we wanted to, we could capture all interactions that every user makes with the app. At the very least, we probably want to capture the user prompts, the generated responses, and a feedback indicator (like/dislike) and/or natural language feedback.
A good exercise is to create some data structures that will represent this data on the receiving end.
from typing import List
from pydantic import BaseModel, Field
class Message(BaseModel):
id: str = Field(..., description="The unique ID of the message.")
conversation_id: str = Field(..., description="The unique ID of the conversation.")
role: str = Field(
...,
description="The role of the message sender (e.g. system, user, assistant).",
)
content: str = Field(..., description="The text content of the message.")
rating: str = Field(
"",
description="User provided rating for the message, e.g. like/dislike or a numerical score.",
)
feedback: str = Field("", description="User provided feedback for the message.")
timestamp: str = Field(
"", description="The timestamp of the message in ISO 8601 format."
)
class LanguageModel(BaseModel):
id: str = Field(
...,
description="The ID of the language model (e.g. the model ID in Hugging Face).",
)
metadata: dict = Field({}, description="Optional metadata for the language model.")
class Conversation(BaseModel):
id: str = Field(..., description="The unique ID of the conversation.")
model: LanguageModel = Field(
..., description="The language model used in the conversation."
)
username: str = Field(..., description="The name of the user in the conversation.")
messages: List[Message] = Field(
[], description="The list of messages in the conversation."
)
This allows us to capture each conversation users have with the model. Each message has feedback information associated with it so we know how to retrain the model. If we’re using an event-based storage mechanism (e.g. Ensign), we can update this info incrementally as users are interacting with the app.
For example, we might define the following events for updating an existing conversation.
import os
import time
import ulid
import gradio as gr
from enum import Enum
from typing import List
from pyensign.events import Event
from pyensign.ensign import Ensign
from pydantic import BaseModel, Field
from huggingface_hub import AsyncInferenceClient
class ModelChatApp:
def __init__(self, endpoint: str, feedback_topic: str = None):
self.endpoint = endpoint
self.feedback_topic = feedback_topic
self.conversation = None
if self.feedback_topic:
self.ensign = Ensign()
self.client = AsyncInferenceClient(
self.endpoint,
)
self.model_info = LanguageModel(
id=endpoint,
)
async def publish_event(self, event):
await self.ensign.publish(self.feedback_topic, event)
def index_to_id(self, index):
"""
Convert a message index (2-dimensional tuple with user/assistant messages) to a unique message ID.
"""
return str(index[0] * 2 + index[1] + 1)
def select_message(self, data: gr.SelectData):
"""
Handle the user selecting a message to provide feedback.
"""
return self.index_to_id(data.index), data.value
async def get_response(self, message, history):
"""
Stream the response from the model.
"""
messages = []
for user, assistant in history:
messages.append({"role": "user", "content": user})
messages.append({"role": "assistant", "content": assistant})
messages.append({"role": "user", "content": message})
stream = await self.client.chat_completion(
messages=messages, stream=True, max_tokens=64
)
if self.feedback_topic:
if not self.conversation:
# Create conversation if it doesn't exist
self.conversation = Conversation(
id=str(ulid.ULID()),
model=self.model_info,
)
event = Event(
self.conversation.model_dump_json().encode("utf-8"),
mimetype="application/json",
schema_name=EventType.START_CONVERSATION,
)
await self.publish_event(event)
# Add the user message to the conversation
user_message = Message(
id=str(len(history) * 2 + 1),
conversation_id=self.conversation.id,
role="user",
content=message,
timestamp=time.strftime("%Y-%m-%dT%H:%M:%S"),
)
event = Event(
user_message.model_dump_json().encode("utf-8"),
mimetype="application/json",
schema_name=EventType.ADD_MESSAGE,
)
await self.publish_event(event)
# Stream out the response
output = ""
async for chunk in stream:
output += chunk.choices[0].delta.content
yield output
# Add the full response to the conversation
if self.feedback_topic:
assistant_message = Message(
id=str(len(history) * 2 + 2),
conversation_id=self.conversation.id,
role="assistant",
content=output,
timestamp=time.strftime("%Y-%m-%dT%H:%M:%S"),
)
event = Event(
assistant_message.model_dump_json().encode("utf-8"),
mimetype="application/json",
schema_name=EventType.ADD_MESSAGE,
)
await self.publish_event(event)
async def vote(self, data: gr.LikeData):
"""
Handle user ratings of individual messages (like/dislike).
"""
if self.feedback_topic:
update = UpdateMessage(
id=self.index_to_id(data.index),
conversation_id=self.conversation.id,
rating="like" if data.liked else "dislike",
)
event = Event(
update.model_dump_json().encode("utf-8"),
mimetype="application/json",
schema_name=EventType.UPDATE_MESSAGE,
)
await self.publish_event(event)
async def submit_feedback(self, message_id, feedback):
"""
Handle the user submitting natural language feedback for a message.
"""
if self.feedback_topic and feedback.strip() != "":
update = UpdateMessage(
id=message_id,
conversation_id=self.conversation.id,
feedback=feedback,
)
event = Event(
update.model_dump_json().encode("utf-8"),
mimetype="application/json",
schema_name=EventType.UPDATE_MESSAGE,
)
await self.publish_event(event)
return ""
async def end_conversation(self):
"""
End the conversation, this happens when the user clears the chat.
"""
if self.feedback_topic:
if self.conversation:
conversation = EndConversation(id=self.conversation.id)
event = Event(
conversation.model_dump_json().encode("utf-8"),
mimetype="application/json",
schema_name=EventType.END_CONVERSATION,
)
await self.publish_event(event)
self.conversation = None
return None, ""
def run(self):
"""
Run the app and handle user interactions.
"""
with gr.Blocks() as app:
# Chat interface
chatbot = gr.Chatbot(render=False)
chatbot.like(self.vote)
textbox = gr.Textbox(placeholder="Enter a message...", render=False)
clear = gr.Button("🗑️ Clear", render=False)
interface = gr.ChatInterface(
self.get_response,
chatbot=chatbot,
textbox=textbox,
retry_btn=None,
undo_btn=None,
clear_btn=clear,
)
# Feedback interface
selected_index = gr.State()
feedback_area = gr.Textbox(
label="Model feedback",
placeholder="Click on a message to provide feedback",
interactive=True,
)
chatbot.select(
self.select_message,
None,
[selected_index, feedback_area],
)
feedback_button = gr.Button("Submit feedback")
feedback_button.click(
self.submit_feedback, [selected_index, feedback_area], feedback_area
)
clear.click(self.end_conversation, None, [selected_index, feedback_area])
app.launch()
if __name__ == "__main__":
# Load configuration variables from the environment
endpoint = os.environ.get("MODEL_ENDPOINT")
feedback_topic = os.environ.get("FEEDBACK_TOPIC", None)
app = ModelChatApp(endpoint, feedback_topic=feedback_topic)
app.run()
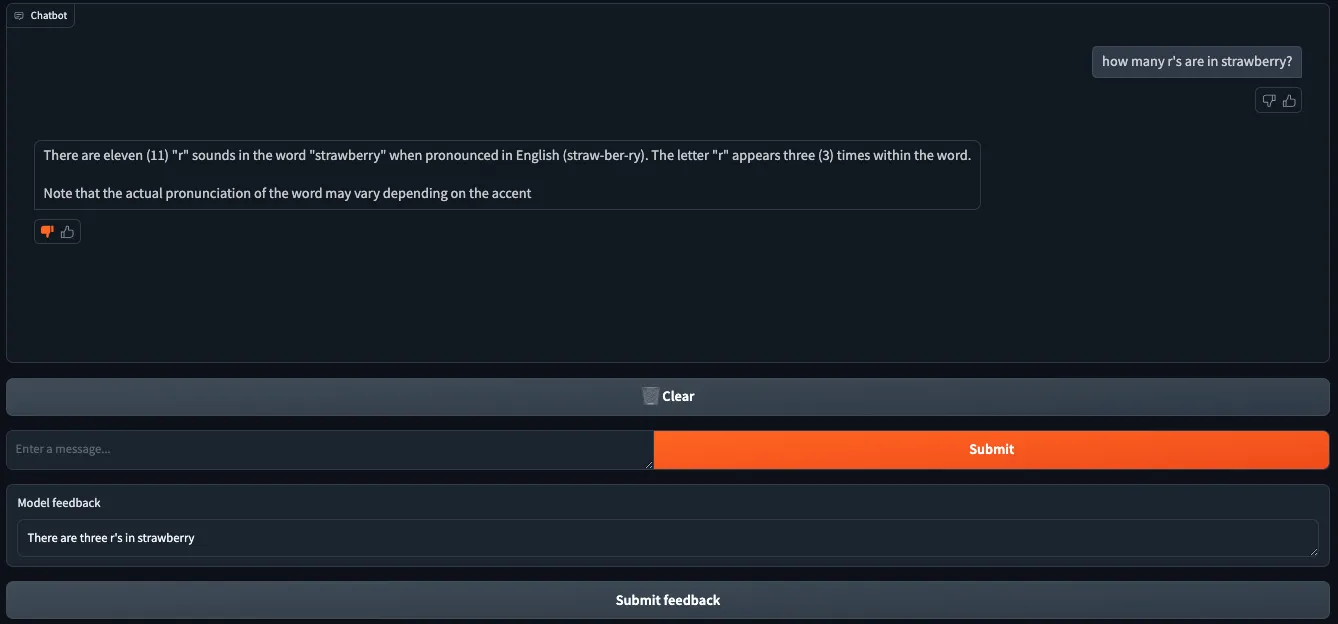
Ingesting user feedback for model tuning
The advantage of event-based capturing is that we can reconstruct the conversations with user feedback at any point in time. Here’s how to do it with PyEnsign:
ensign = Ensign()
cursor = await ensign.query("SELECT * FROM test-feedback OFFSET 239")
async for event in cursor:
data = json.loads(event.data.decode("utf-8"))
print(event.type, data)
start_conversation v0.0.0 {'id': '01J7PTGBKBEYJHJAMZ9Q9EE9SD', 'model': {'id': 'HuggingFaceH4/zephyr-7b-beta', 'metadata': {}}, 'messages': []}
add_message v0.0.0 {'id': '1', 'conversation_id': '01J7PTGBKBEYJHJAMZ9Q9EE9SD', 'role': 'user', 'content': "how many r's are in strawberry?", 'rating': '', 'feedback': '', 'timestamp': '2024-09-13T18:11:48'}
add_message v0.0.0 {'id': '2', 'conversation_id': '01J7PTGBKBEYJHJAMZ9Q9EE9SD', 'role': 'assistant', 'content': 'There are eleven (11) "r" sounds in the word "strawberry" when pronounced in English (straw-ber-ry). The letter "r" appears three (3) times within the word.\n\nNote that the actual pronunciation of the word may vary depending on the accent', 'rating': '', 'feedback': '', 'timestamp': '2024-09-13T18:11:48'}
update_message v0.0.0 {'id': '2', 'conversation_id': '01J7PTGBKBEYJHJAMZ9Q9EE9SD', 'rating': 'dislike', 'feedback': ''}
update_message v0.0.0 {'id': '2', 'conversation_id': '01J7PTGBKBEYJHJAMZ9Q9EE9SD', 'rating': '', 'feedback': "There are three r's in strawberry"}
Train impactful models
Training models that users actually want to use requires an infrastructure for capturing honest user feedback. Setting up these feedback mechanisms requires a bit of engineering work, but the result is the ability to train generative models that can be validated and improved by both developers and end users.
AI Image Generated with Leonardo.ai








