

Thinking about using a large language model (LLM) at your organization? Check out this tutorial to see how to bootstrap an MVP using an open source pre-trained model from HuggingFace and a free Ensign account.
“How can I build my own LLM? ChatGPT is a black box; I can’t customize it.” “Don’t LLMs need trillions of samples? We don’t have enough data.” “LLMs are too complicated - I don’t even know where to begin.”
Sound familiar? This is for anyone out there who knows they have a good use case for LLMs but has found themselves stymied. Trust us. You can totally do this. In this post, we will walk through an end-to-end solution for bootstrapping an LLM and deploying it for real time classification.
🎥 You can also watch an on-demand recording of this tutorial, delivered by Rotational Labs Distributed Systems Engineer, Prema Roman.
😎 Just here for Prema’s code? Here’s the repo!
A Very Relatable Use Case (Sentiment Classification)
Imagine you work in the Customer Success Department at a large seafood chain restaurant. Customer complaints are being addressed way too slowly, sometimes a week or two after the fact. Serious complaints need to be flagged for Legal because they require mitigation to avoid lawsuits and negative public opinion. But your restaurant serves 85M customers every year and the helpdesk is drowning in complaints that come through phone and email… not to mention those that are posted on social media.
Yikes.
But then you realize you can use an LLM to analyze the social media posts and bucket them into positive and negative reviews and automatically triage them much faster!
Designing the Solution
When designing data science applications, it’s important to remember that 87% of data science projects never make it to production. Teams that are new to operationalizing ML have a tendency to make premature decisions that fail to foster organizational buy-in, cause scaling/operations problems later on, or make deployment unnecessarily challenging.
So when it’s time to build a data science application, it’s important to take a step back and consider the specific use case and organizational context at hand. If you/your team are new to applications development, it’s worth it to cultivate allies from the Engineering team who can help advise you. Application design is not something that most of us learn in data science or machine learning education (from our experience, it’s not something that’s typically taught even in computer science programs). Design is hard, because it depends on having some intuition about things that can go wrong in an application, which gets easier the more experience you have.
How else can you prevent your project from being one of the 87% of unsuccessful ones?
- Keep the end goal in mind and prioritize the success of that objective over ancillary ambitions
- Don’t strive for perfection, iterate (take a cue from Engineering projects)
- Feedback loops are important! This helps you with iterating your solution. Feedback can mean both automated feedback (e.g. continuous monitoring and evaluation), and human feedback (i.e. from the people who are the customers of the solution)
- Communication is key. Understand the objectives and pain points of the other teams you work with
- Work with engineering and platform teams to build good development practices to ensure that you have maintainable code and processes
Data Annotation & Architecture
So we collaborate with our friend from Engineering to sketch out an Application Overview (left side of the below image). Now let’s take a crack at architecting the NLP internals and modeling component of our solution.
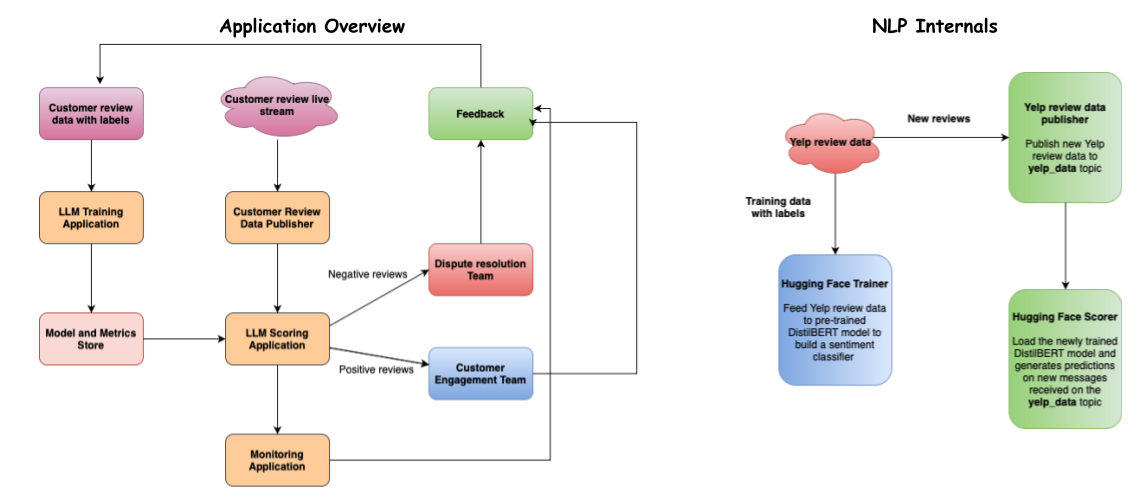
This is the basic blueprint for our streaming analytics/inference application.
As with all classification problems, the first step is to get labeled data. For this hypothetical use cases, let’s say you team up with some colleagues from the Customer Service team, gather all of the relevant the social media posts you can find, and work together to label them as positive or negative. That will give you a label which the application can use to train the supervised model. Each model you train you will then store together with model metric metadata in your chosen storage tool.
Next, you can start to set up a routine ingestion process to ingest social media posts as soon as the customer posts something on social media. Data ingestion is managed using the pub/sub design pattern, so that we can read in new data (customer reviews) and generate predictions immediately. Predictions will enable automated labeling of reviews as positive and negative, and all negative reviews will get triaged for dispute resolution and positive reviews will get routed to the customer engagement team.
Leveraging Open Source
There are many open source tools available to get you started. In this tutorial, we’ll focus on two:
- HuggingFace has a large selection of pre-trained models, including ones from Google, Microsoft, and Meta, that you can choose from for your specific task. You can also further customize these pre-trained models by feeding your own data, a process called transfer learning, and use your domain knowledge and data science intuition to tune the knobs of these models to achieve the outcomes you are looking for.
- Ensign is a distributed eventing system. It stores chronological changes to all objects, which you can query with SQL to get change vectors in addition to static snapshots. It can be used to help with ingestion, training, deployment, and continuous evaluation. For this example, we’ll use Ensign’s Python SDK to deploy the pretrained HuggingFace model on a stream to transform it into a real time prediction generator.
Bootstrapping the LLM
The sentiment analysis application will use the DistilBERT model from HuggingFace. The components of the HuggingFace training process include the TrainingArguments (parameters to pass to the Trainer class), and the Trainer.
The first step for bootstrapping our LLM is to prepare our TrainingArguments. This will allow us to take the pre-trained model and augment it with whatever labeled training data we have been able to acquire/annotate (it takes less than you might think).
The TrainingArguments is a essentially a dictionary with a huge list of learning parameters. We’ll pass these params as well as the directory where we want to save the models to after each run.
self.train_dir="trained_models"
params={
"learning_rate": 2e-5,
"per_device_train_batch_size": 4,
"per_device_eval_batch_size": 4,
"num_train_epochs": 3,
"optim": "adamw_torch",
"weight_decay": 0.01,
"save_strategy": "epoch",
"evaluation_strategy": "epoch",
"metric_for_best_model": "f1_true",
"load_best_model_at_end": True,
"push_to_hub": False,
}
self.training_args = TrainingArguments(**params,output_dir=self.train_dir)
Next, we initialize the pre-trained model and tokenizer using the DistilBert model assets available from HuggingFace. Note: If you were to want to use a different tokenizer or a different model, all you have to do is change this name.
self.tokenizer=DistilBertTokenizer.from_pretrained(
"distilbert-base-uncased-finetuned-sst-2-english"
)
self.model = AutoModelForSequenceClassification.from_pretrained(
"Distilbert-base-uncased-finetuned-sst-2-english"
)
Now we want to tokenize this data set before we feed it to the model. In this case, imagine we have a Pandas dataframe in this in this case, so we’re going to convert it to a Dataset object, which is a HuggingFace class. We will apply this pre-processing function to both the train and the test data.
def preprocess_function(self, instances):
return self.tokenizer(
instances["text"], truncation=True, padding="max_length"
)
# convert from pandas dataframe to a Dataset object
train_dataset = Dataset.from_pandas(train_df)
test_dataset = Dataset.from_pandas(test_df)
# Use the preprocess_function to tokenize the data
tokenized_train = train_dataset.map(
self.preprocess_function, batched=True
)
tokenized_test = test_dataset.map(self.preprocess_function, batched=True)
Note: By setting batched=True, we can ensure that this pre-processing happens in batches.
Next, we set up the Trainer class and run the training process:
trainer = Trainer(
model=self.model,
args=self.training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
tokenizer=self.tokenizer,
compute_metrics=self.generate_metrics,
)
trainer.train()
metrics = trainer.evaluate()
print(metrics)
# save the best model based on evaluation metrics
trainer.save_model(self.model_dir)
Congratulations! You have officially bootstrapped your own LLM!
Enabling Real Time Predictions
Now it’s time to enable real time predictions. We need to set up a stream so that data can flow into and out of the model we bootstrapped in the previous section.
For this we will use the concept of Publishers and Subscribers from Ensign, an open source eventing platform for data scientists:
Our ScoreDataPublisher will send data to our model:
class ScoreDataPublisher:
def __init__(self, topic="yelp_data", interval=1):
self.topic = topic
self.ensign = Ensign()
self.interval = interval
def run(self):
asyncio.get_event_loop().run_until_complete(self.publish())
async def publish(self):
await self.ensign.ensure_topic_exists(self.topic)
score_df = pd.read_csv(os.path.join("data", "yelp_score.csv"))
score_dict = score_df.to_dict("records")
for record in score_dict:
event = Event(
json.dumps(record).encode("utf-8"),
mimetype="application/json"
)
await self.ensign.publish(
self.topic,
event,
on_ack=print_ack,
on_nack=print_nack
)
await asyncio.sleep(self.interval)
Next, we’ll build our predictor, the HuggingFaceScorer, which will allow our application to subscribe to the yelp_data topic and asynchronously generate predictions:
class HuggingFaceScorer:
def __init__(self, topic="yelp_data", model_dir="final_model"):
self.topic = topic
self.model_dir = model_dir
self.ensign = Ensign()
self.load_model()
def run(self):
asyncio.get_event_loop().run_until_complete(self.subscribe())
def load_model(self):
tokenizer = DistilBertTokenizer.from_pretrained(
"distilbert-base-uncased-finetuned-sst-2-english"
)
model = AutoModelForSequenceClassification.from_pretrained(
self.model_dir
)
self.classifier = pipeline(
"sentiment-analysis",
model=model,
tokenizer=tokenizer
)
async def generate_predictions(self, data):
text_list = []
text = data["text"]
text_list.append(text)
pred_info = self.classifier(text_list)
pred = 0 if "NEGATIVE" in pred_info[0]["label"] else 1
pred_score = pred_info[0]["score"]
label = data["labels"]
print(text)
print(f"prediction: {pred}, prediction_score: {pred_score}, label: {label}")
async def subscribe(self):
await self.ensign.ensure_topic_exists(self.topic)
async for event in self.ensign.subscribe(self.topic):
data = await self.decode(event)
await self.generate_predictions(data)
To test drive your real time sentiment classification application, run your HuggingFaceScorer in one terminal, and your ScoreDataPublisher in a separate terminal.
That’s it! You can watch the video here and find all the code here.
Conclusion
As you’ve seen in this post, you can start incrementally delivering insights to your organization without needing to resort to purchasing a pricey proprietary solution, or waiting to accumulate a trillion rows of data. Using the bootstrapping pattern and open source, Python-friendly resources like HuggingFace and Ensign, you can empower your roadmap — you’re set up to implement your own custom LLM by simply swapping out the data and model (no tech debt required).
Ready to take the next step? Check out MLOps 201: Data Flows for Real Time Model Inferencing.
Ready to experiment with data streams and change data capture? Check out The Data Playground and set up your own free Ensign account.
Photo by Francesco Veronesi on Flickr Commons









