Sick of hearing about hyped up AI solutions that sound like hot air? 🧐 Let’s use boring old ML to detect hype in AI marketing text and see why starting with a simple ML approach is still your best bet 90% of the time.
In our first post in this responsible LLM series, we discussed that while LLMs have unlocked new use cases that companies can leverage to generate more revenue, they are not the catch-all solution for every single AI use case. We identified the following drawbacks:
- High energy consumption
- Difficulty understanding and documenting the underlying data used
- Difficult to deploy, maintain, and monitor software applications using LLMs due to added complexity
In this blog post we talk through a project to illustrate why you should always start by using simpler ML models that show promise and then iterate and scale up as needed.
How Do You Get Your News?
Using social media for news isn’t a good or bad thing. Heck, we do it too. But with all the buzz about magic AI solutions clogging up our newsfeeds, developing a model to detect online hype felt like a great use case to test out.
If you’re like many adults in the U.S. there’s a great chance that you get your news from social media. According to the Social Media and News Fact Sheet published by the Pew Research Center, 17% of U.S. adults often used social media outlets for news in 2022. During that same year, 33% of U.S. adults shared that they sometimes use social media to obtain news. Per the same report, in 2023, the most popular social media sites for those who use social media for news were Twitter, Facebook, and TikTok.
We figured that it would be easy to find a big dataset to get started developing a specialized model capable of differentiating hyped-up marketing jardon.
Don’t Believe the Hype
But, first, we had to define “hype” in a way that a model can understand.
After deciding to use a LinkedIn Influencer dataset from Kaggle, we took to the task of labeling a subset of the posts as hype or not_hype. We split up the work and each took on a chunk of the data to label. But after a little baselining using simple scikit-learn classifiers suggested low accuracy, we wondered if the categories — hype and not_hype — were a little too broad and decided to come up with more granular categories, as follows:
| Category | Number of posts |
|---|---|
| Clickbait | 157 |
| Promotion | 116 |
| Opinion | 54 |
| News | 34 |
| Motivational | 15 |
| Other | 15 |
We tried a number of classification models, but were not able to produce a suitable model, though given the extremely small number of instances for each category, this was not a huge shock.
Here is a look at the Uniform Manifold Approximation and Projection (UMAP) projection of all of the LinkedIn posts. This visualization shows that there is a lot of overlap between embeddings attributed to each of the categories, which helps explain why it was challenging to find a model that performed well.
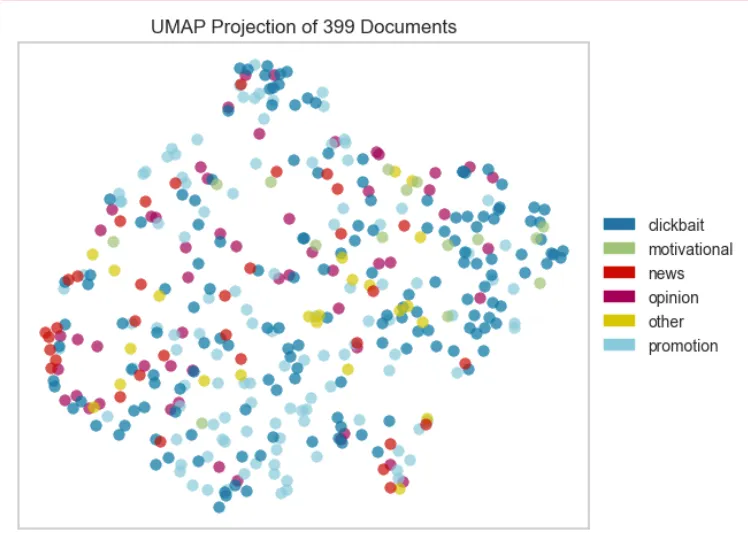
While we did talk across the team about how each of us defined “hype” and what the subcategories might be, this is a good reminder that data annotation can introduce noise, especially when the target is something that’s in the eye of the beholder!
After further analysis we decided to combine the clickbait and promotion categories into the hype category, as the intention behind both types of posts is to get the audience’s attention towards the product, service, or idea the influencer was promoting. The other categories were combined into a second category we called non_hype. We achieved the best performance using the open source package XGBoost.
Here are the precision, recall, and f1 scores for both classes:
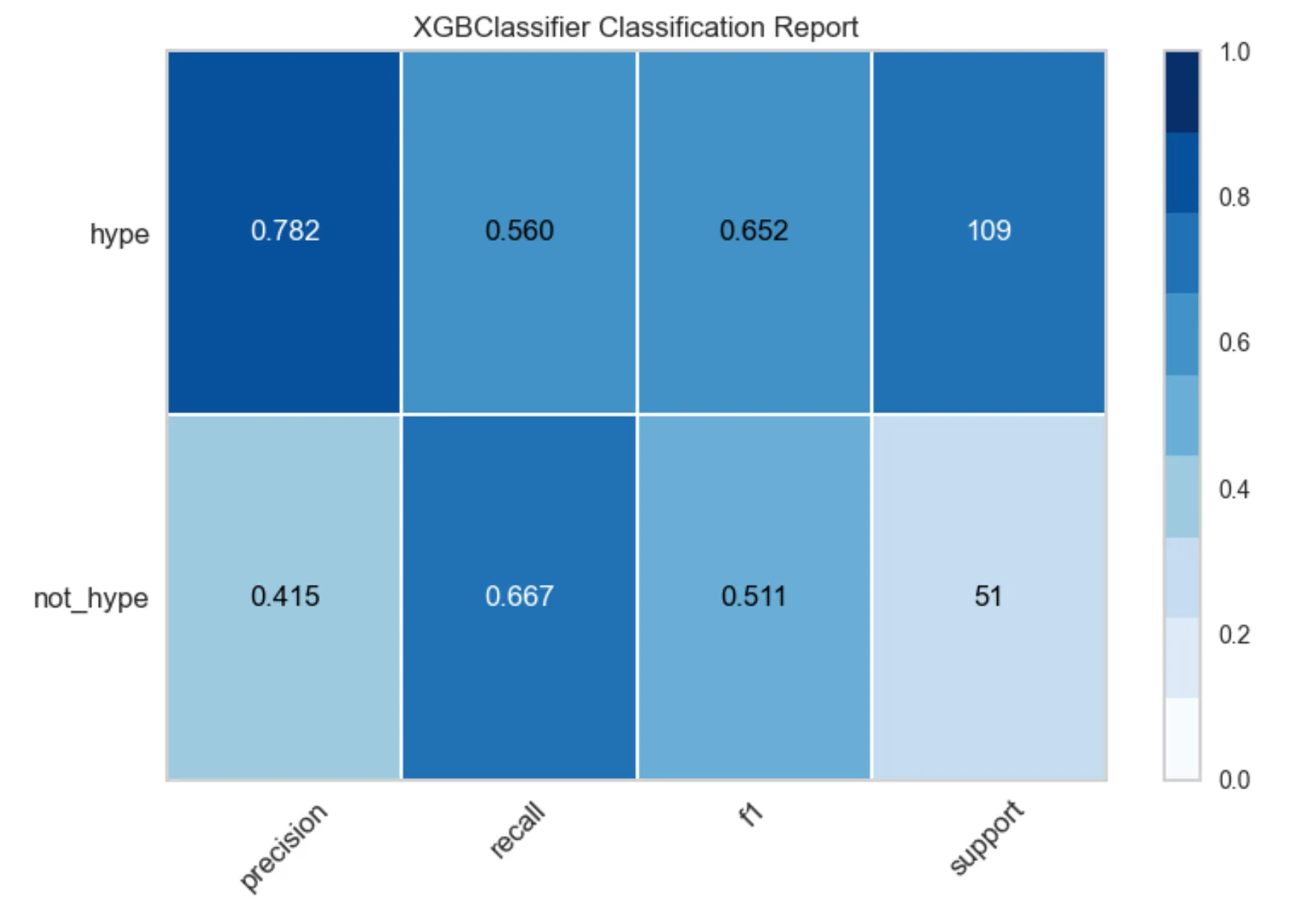
These results are not that bad considering that we did not perform any hyperparameter tuning on the model and had only labeled 399 instances. Here are the model inferences on a couple of examples. The first example is a post where the influence is promoting their talk on a podcast. The model scored the post as hype.

The following example is an education post on how to improve LLM performance. The model scored the post as not_hype.

Let’s Go to Production! Scope Next Steps 😉
While our model isn’t quite ready for production (stay tuned though!), now we can do a much better job costing out a more complete solution. Here’s what we’ve gained:
- A better definition of our problem (what is “hype”?)
- A clearer sense of our targets for prediction
- A strategy for data annotation and some inter-reviewer concordance about using the labels.
- A better understanding of the vocabulary and structural patterns (aka features) that our LLM will have access to.
- Enough information from the baseline models to make a “go” or “no go” decision.
We hope this example demonstrates why it make sense to start simple! All of this work was done in less than a month, using our laptops, not expensive cloud infrastructure.
As experts in developing applied machine learning solutions, we routinely start with simple models before we scale out so we can plan and de-risk projects. These quick LLM litmus tests are critical to our process for developing effective automations with LLMs. In fact, we see this as a core part of our responsibility to our clients.
Recently we were tasked with building a domain-specific language model attuned to a very specific business process for one of our clients. We started with some simple models to establish an inferencing API and an experimental framework, and then swapped the model out with a custom transfer-learned DistilBERT model to meet the client’s goal. It was in production after only 6 months and now saves 20 hours of analyst time per week.
So we aren’t saying not to dive headfirst into Hugging Face. We’re reminding you to keep your AI systems as simple as possible, and this responsibility should really start with the data science/research team.
While researchers often get hung up measuring the success of their models in terms of tokens and F1 scores, remember that simplicity is critical to getting models into production. These are some of the benefits:
- Simpler systems are cheaper and easier to maintain
- Simpler systems foster easier collaboration among teams
- Simpler systems allow for rapid iteration
- Simpler systems are more profitable
Aiming for simplicity also means that companies can leverage a larger and more generalized talent pool whose diverse perspectives enables organizations to build truly innovative products, i.e., there is no need to be competing for the limited number of people who have a narrow view of what it takes to innovate in the AI space.
Photo by camilo jimenez on Unsplash