

I spent last week in San Francisco meeting up with the Rotational team to attend PyTorch Conference. If you’re an LLM developer and didn’t make it this year, here are some of my key highlights and takeaways.
PyTorch is increasingly becoming a most-loved tool in the toolbelt for many of us who build and finetune language and computer vision models, and this year Rotational was excited to give back to the community as a conference sponsor. One of the coolest things about having a sponsor booth is that you get to talk to a lot of people about what stood out most to them about the conference. Here are some of the main things people were talking about:
PyTorch-Native LLMs Are Here
Exciting developments with TorchTitan, TorchTune, and TorchChat provide a more streamlined workflow where you can build, finetune, and deploy models directly in PyTorch.

Simplicity Wins
For a long time, the way to make deep learning models better was to make them more complex, but the popular opinion is starting to shift. In his talk on the evolution of LLM architectures, Sebastian Raschka explained that there is a growing trend towards simpler models.
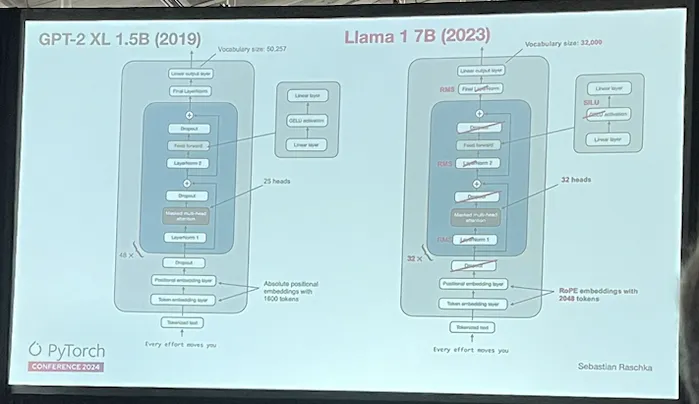
For instance, Llama 1 7B ditched the Dropout layers and swapped LayerNorm for the simpler RMS. Simplifying these model architectures makes training, tuning, and deployment easier, and doesn’t seem to handicap model performance as much as everyone used to think it would.
Data Over Hardware
One of the most consistent themes across the talks at PyTorch was the criticality of high quality training data. It turns out that high-quality data can accelerate training faster than expensive hardware upgrades and more effectively than better algorithms.
This calls to mind the old adage that “more data beats better algorithms” (perhaps it should be updated to “better data beats better algorithms”).
Unfortunately, data quality is one of the things that AI developers rarely control, which has driven most of us to explore more complex algorithms and GPUs. But for the executives and decision-makers out there, spending more on quality data will take you further than spending more on hardware.
Context Matters in Testing
Testing models is hard, which as Chip Huyen pointed out in her keynote, “Why You Should Think Twice Before Paying for an Evaluation Tool,” is complicating the development of general-purpose LLM training and evaluation platforms.
Huyen pointed out that models are also increasingly contextual, meaning that at least some of the evaluation criteria should be model-specific. For instance, if we perform transfer learning on a pre-trained HuggingFace model using a domain-specific dataset, we could quantify how much better the model performs on domain-specific tasks compared to the base model.
Model Depth vs. Size
For a long time, there hasn’t been a clear rule of thumb on how to tune LLM model parameters to improve models for information retrieval versus other more complex tasks. Tuning often requires significant experimentation that can sometimes look more like art than science.
Several speakers and attendees mentioned recent research which suggests that shallow layers can effectively encode simple knowledge bases, while complex reasoning tasks need deeper layers. In other words, to make models “smarter” we may first need to determine if our primary goal is more knowledge or better reasoning.
Final Thoughts
PyTorch Conference is still oriented towards core developers (most open source package-oriented conferences start out this way, in my experience), and most of the talks were oriented towards issues faced by teams at companies like Meta, NVIDIA, Google, and Intel. There were tons of talks about topics like auto-sharding, hardware acceleration, and ML on the edge. It was fascinating to hear how these organizations understand the current state-of-the-art, and how the PyTorch API is evolving. Next year I’ll bet there will be more talks from practitioners (i.e. AI/ML use cases and “what we built with PyTorch”).
The PyTorch/Tensorflow flame wars feel like a long time ago. Incubated at Google, TensorFlow was open-sourced first (~2016) and initially dominated the deep learning field with its stable API (thanks largely to Keras), and the novel visual diagnostics of Tensorboard. PyTorch was open-sourced by Facebook a year later and has steadily gained popularity, particularly since the release of the v1.0 API. Back in the late 2010’s, machine learning practitioners were increasingly talking about much more pythonic PyTorch was compared to Tensorflow, but there was a sense that it wasn’t quite as production-ready. Today, both frameworks are still widely used.
One message came through loud and clear in the 2024 conference — PyTorch is evolving to support generative AI use cases. Given how complex and painful LLM development is for those of us in the trenches right now, this could give PyTorch the edge over other AI/ML frameworks.
If you attended PyTorch this year, let us know what stood out most to you!









