

If you struggle to build analytics and models that keep up with changing data, it might be because you haven’t yet learned to think about data in terms of topics. In this module, learn how by solving a real-world, real-time problem!
Check out Part One and Part Two of this series if you missed them!
How Relational Databases Cause Model Drift
Our favorite SQL databases (PostgreSQL, sqlite, DuckDB, etc) are fantastic for working with tabular data, but at best they only tell us the current state of our data. But what if our analytics need to model how that data is changing over time (e.g. model drift, concept drift, data drift)? What if we need to compare the current state of our data to what it looked like this time last year?
If you find yourself asking the above questions, it’s a good sign that you might benefit from reframing your thinking from the static perspective of data (aka “snapshots”) to a streaming perspective.
You can encourage this reframing using a technique called change data capture (CDC), which is a method for capturing the individual changes to a database over time.
Ensign is a great way to instrument change data capture, since it can be used to reconstruct the state of your relational database at any point in time, reprocess previously consumed data in the exact same order that it was produced (for model reproducibility), or identify data drift in real-time.
How to Think in Topics
An Ensign topic is a globally ordered and globally distributed stream of events. They are somewhat analogous to the concept of tables in a relational database, however there are a few important differences:
| Property | Tables | Topics |
|---|---|---|
| Mutability | Can create, read, update, delete rows | Events are immutable - can only publish new Events |
| Heterogenity | Columns usually have singular data types | Events can have varying data types and schemas |
| Ordering | Rows are not explicitly ordered and ordering usually happens at query time | Events have a defined ordering and the ordering is consistent across replicas |
Consider a retail store that tracks inventory using a relational database. It might have one table called Products so that new products can be registered and their prices can be updated regularly, and another table called Inventory with foreign key relationships to view and update the availability of specific products within the store.
If we were to redesign this as an event-driven architecture, we might include a product-updates topic to track updates to product names, prices, etc. and an inventory-updates topic to track changes to product inventory. The individual events are updates to those topics, similar to how we would use the ADD, UPDATE, and DELETE SQL keywords to update rows in the relational database.
Here, the topics track the changes to the products and inventory rather than just the current state of the inventory.
Designing Data Flows
Now let’s return to our flight-tracking project from Part One of this course.
Suppose we want to track aircraft flights in the hopes of building a real-time model to predict flight delays. One of the first steps is to think about what kinds of data will be flowing through the application.
- The positions of ongoing flights.
- The trained models and the data they were trained on.
- The arrival predictions made by the models.
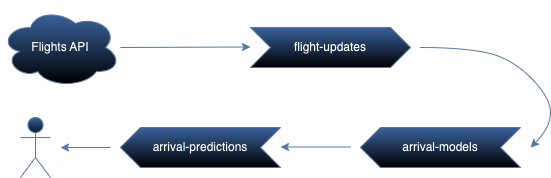
The above diagram loosely represents how the data will flow through the application. We will ingest data from an API into a flight-updates topic, use it to train real-time models for the arrival-models topic, and eventually expose model inferences to users via the arrival-predictions topic.
One advantage of event-driven architectures is that the topics are completely decoupled. Each component of the application can be tested independently, and we can feel free to experiment without breaking the prototype. For example, if we want to include weather data as a feature for model training we can simply add a weather-updates topic.
To be continued…
In the next module, you’ll create a real-time publisher to query an API and publish flight data to Ensign!
Photo by Jérôme Prax on Unsplash







