

Looking for a middle ground between custom LLMs and traditional ML? Please welcome semantic search to the stage! Let’s use semantic search to predict which film will take home the “Best Picture” Oscar this year 🤩
Last year we all went to see “Everything Everywhere All at Once” at our team retreat, and it went on to take home several awards, including Best Picture. Let’s see if we can predict the future again!
Data Ingestion
To start, there is a nice dataset on Kaggle which compiles all the Oscar nominees and winners since 1927. It turns out that the best picture award has changed names several times, so it took some manual data engineering to extract the labels.
>> bp = [
'BEST PICTURE', 'BEST MOTION PICTURE', 'OUTSTANDING PICTURE',
'OUTSTANDING PRODUCTION', 'OUTSTANDING MOTION PICTURE'
]
>> df = df[df['category'].isin(bp)]
>> df['winner'].value_counts()
winner
False 496
True 95
Name: count, dtype: int64
There have been 591 best picture nominees and 95 winners over the years. Not the largest data set, but at least the class imbalance isn’t terrible. To do machine learning I needed features so I scraped text from Wikipedia. Most films have a corresponding Wikipedia in the format:
wikipedia.org/wiki/{film_title}_({year}_film)
However as you might imagine this is not 100% consistent; it really just depends on how unique the film title happens to be. It was guessable enough to eventually get all 591 film articles into the DataFrame. I used beautifulsoup to extract the text from the downloaded HTML.
from bs4 import BeautifulSoup
df["text"] = df["wiki"].apply(lambda x: BeautifulSoup(x, 'html.parser').get_text())
df["cleaned_text"] = df["text"].apply(lambda x: x.replace("\n", " ").replace("\'", "'"))
df["cleaned_text"].iloc[0]
'The Racket is a 1928 American silent crime drama film directed by Lewis Milestone and starring Thomas Meighan, Marie Prevost, Louis Wolheim, and George E. Stone...'
A TSNE projection is one way to visualize the high-dimensional data (e.g. encoded documents with TF-IDF). It shows that there are at least some interesting clusters in the Wikipedia text. The green dots are the winners.
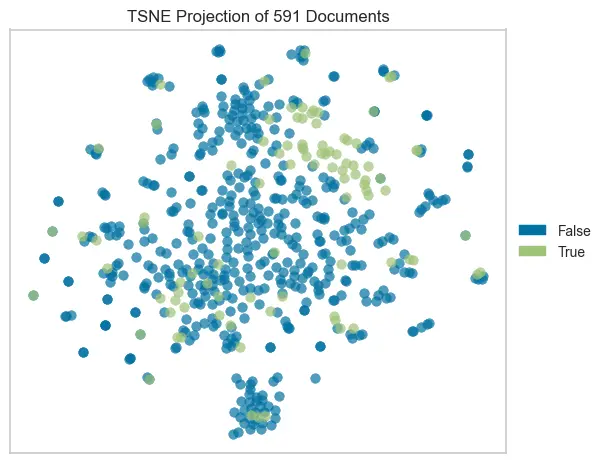
Initial Models
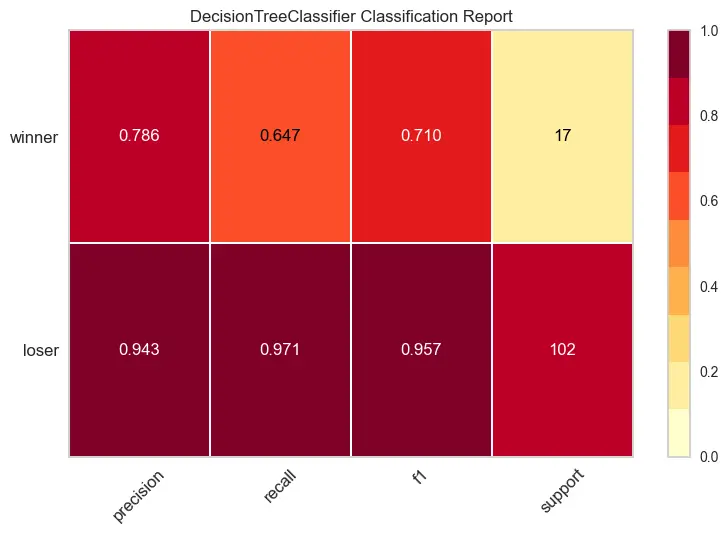
My first idea was to encode the article text with a tried-and-tested approach like TF-IDF and fit a binary classifier using the encoded vectors as features. The best model was pretty overfit due to the small size of the training set.
The next idea was to train distilbert for sequence classification to take advantage of the massive amount of pre-training. I was able to train a “will it win” model but the inferences were still not useful. Everything looks like a winner this year!
Semantic Similarity
Given that there is so little training data, perhaps a similarity approach makes more sense. If we make the assumption that films similar to other Oscar winners are more likely to win, then we have a well-defined methodology to select the most probable winner.
The first step to computing similarity is to encode the articles text into vector space. Here we can take advantage of pre-trained LLMs. There are particular models that have been trained to maximize performance for tasks like semantic search. In this case, we are looking for a sentence transformer model like all-MiniLM-L6-v2 that’s trained for symmetric search (e.g. the query and documents in the corpus are about the same length).
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
best_pictures["embeddings"] = best_pictures["cleaned_text"].apply(
lambda x: model.encode(x)
)
Now that we have the embeddings we can compute the similarity between an arbitrary bit of text and all the films in the corpus. Ranking by similarity gives us the “nearest neighbors” to a particular film.
from sentence_transformers import util
def get_most_similar(text, n=3):
embeddings = model.encode(text)
df["sim_score"] = df["embeddings"].apply(
lambda x: util.cos_sim(embeddings, x).item()
)
return df.sort_values(by="sim_score", ascending=False).head(n)
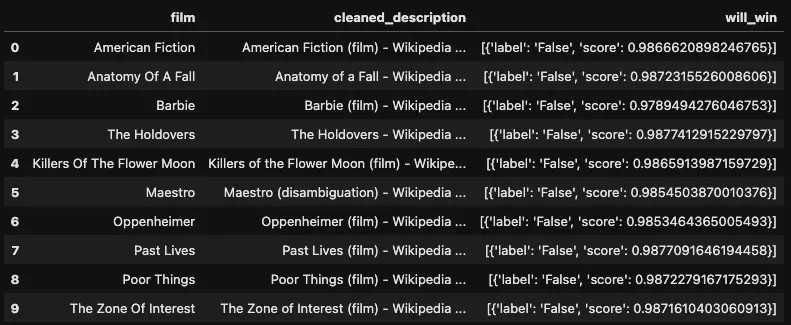
film = "American Fiction"
text = eval_df[eval_df["film"] == film]["cleaned_text"].iloc[0]
get_most_similar(text, n=10)[["film", "sim_score", "winner"]]
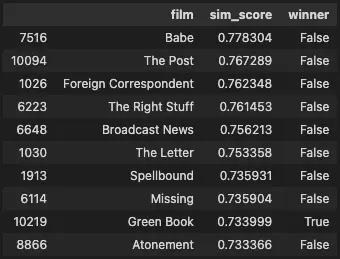
From here it’s a matter of creating some algorithm to produce a final ranking for this year’s nominees. One approach might be to take the top n similar films and multiply the proportion of winners of that group by the average of the similarity scores.
def win_score(text, n=10):
sim = get_most_similar(text, n=n)
winners = len(sim[sim["winner"]]) / n
return sim["winner"].mean() * winners
eval_df["win_score"] = eval_df["cleaned_text"].apply(lambda x: win_score(x, n=100))
eval_df.sort_values(by="win_score", ascending=False)[["film", "win_score"]]
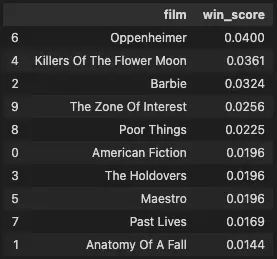
The similarity approach predicts that Oppenheimer will take it home. This is in line with the betting odds as of Friday, March 8.
Oppenheimer -5000
Poor Things +2000
The Zone of Interest +2000
The Holdovers +2500
Anatomy of a Fall +5000
Barbie +6600
American Fiction +8000
Killers of the Flower Moon +10000
Past Lives +15000
Maestro +15000
Conclusion
When you need to boost the performance of your machine learning model, it usually comes down to improving the quality of the training dataset. In cases where you don’t have access to more data or you can’t afford to train custom LLMs, a similarity approach can be a cost-effective (and more explainable) solution. And just as with film, a bit of creativity goes a long way!
Photo by tommao wang on Unsplash








