

If you can’t deploy your models, you might feel frustrated, but you aren’t alone — only 1 in 10 data science projects ever gets deployed. The fix? We need to shift our mental model towards “thinking in events.”
It’s shocking but true: 87% of data science projects never make it into production. This shortfall is an existential threat to data scientists who are struggling to make an impact in their organizations, as expressed in this video:
The good news is that it’s getting easier to engage in Engineering culture as a data scientist. In particular, using event streams to manage models enables data scientists to deploy more models to production and make an impact with their organization and customers.
Event streams (aka data flows), have three key benefits that make this possible:
- They enhance hypothesis-driven development workflows and enable the creation of reproducible and explainable models.
- They allow data scientists to interact with other teams without needing microservice or DevOps chops.
- They allow us to monitor the behavior of our models in deployment, so that we can understand when models require adjustments or adaptations, and trigger retraining.
Read on to learn more about how to leverage event flows to design systems that align with your organization’s communication structure, and get your models to Prod.
What Drives the Data Science Deployment Gap?
As shown in the above video clip, we see three main reasons why the majority of data science projects never make it to production: commercial culture that prioritizes low-risk products, organizational boundaries between different teams, and data silos that hinder access to necessary data.
Commercial Culture
Academic data science programs teach hypothesis-driven design and experimentation. Failure is common and accepted.
But in the business world, companies want minimize risk. Leaders might not be willing to put models into production that have F1 scores of 0.6, or coefficients of determination that are too low.
As a result, the data science team gets increasingly isolated because they can’t push their projects towards the application.
Organizational Boundaries
Effective model management requires cross-functional collaboration between data scientists, software engineers, and product development teams.
If the DevOps team, software engineering, product development, and front-end teams are not organizationally integrated with the data science team, they may not have any incentive to build data science models into their product or into production. It becomes challenging to align goals, share knowledge, and iterate on models efficiently.
A lack of collaboration between different teams impedes MLOps.
Data Silos
Data silos, where data is stored in disparate systems or departments, pose a significant challenge in MLOps.
DBAs and DevSecOps teams can be reluctant to share data access with data scientists, for fear of them crashing the database, introducing bugs, or creating security issues.
These data silos lead to insufficient data for model training, resulting in suboptimal model performance and limited insights.
Deploy to Prod with Event Streams
Event stream architectures increase collaboration without interrupting existing processes and make data science work immediately available to be incorporated into development.
Organizations can create read-only data streams that match the security and privacy policies of that original data source. Then, instead of asking for data access or snapshots, data scientists can stream data out directly and securely to train models and publish model results back to the application.
By utilizing data flows instead of application-based coupling, the need for developers to build systems from different code languages can be eliminated.
Data scientists should be encouraged to deploy the simplest trained model into production and strengthen it over time. Augmenting hypothesis-driven development workflows with streaming MLOps will let organizations:
- Achieve reproducibility, which enables explainability, debugging, and validation
- Decouple models from applications with async inferencing
- Monitor, retrain, and strengthen models
Achieving Reproducibility
Reproducible training is a critical aspect of managing machine learning models, as it enables explainability, debugging, and validation in reproducible training.
Explainability is crucial for understanding how models make predictions, and for guaranteeing transparency. Why does a model produce a result and make the decision that it does? To answer that question, you need to have access to the instances it was trained on.
This is particularly important for debugging exceptionless errors. If we move a model into production and two columns get flipped, the model will attempt to make an inference on incorrect data. We need to be able to retrain the model on the instances it came from.
From Computational Data Stores to Change Data Capture
Computational data stores play a vital role in managing machine learning models. Data scientists use transactional/relational databases or columnar databases. But as the following video clip shows, this can create challenges for MLOps:
Transactional (or relational) databases such as PostgreSQL, MySQL, and Oracle are well-suited to applications. Normal forms deduplicate data and make inserts and updates fast. But if data scientists attempt to use these databases, it creates our first problem with reproducibility, because data routinely changes without provenance information or versioning.
On the other hand, columnar databases (Cassandra, Redshift) offer benefits such as efficient data compression and faster query performance. They’re convenient for data science because they allow for efficient aggregations, projected joins, and queries that read most of the database. Columnar storage makes it easy to append records and perform transformations on individual features. However, it is difficult to identify and/or modify individual records or even subset or sample rows, again creating reproducibility challenges.
In either case, how do you identify the original instances your model was trained on? How can you make explainable references rooted in instances, filter anomalies or bad data? You could snapshot data in a file, but now you have a data management burden.
Change data capture (CDC) is a powerful solution for achieving reproducibility in machine learning models.
Change data capture (CDC) is a powerful solution for achieving reproducibility in machine learning models. It’s part of most database systems, usually referred to as the “write-ahead log” (or WAL).
CDC enables the creation of snapshots or clones of databases without performing transactions on the live production database. Events can be consumed by one or more subscribers to create specific data snapshots between offsets. You can create snapshots in your own local database, and can just store the start offset and end offset to reproduce.
With CDC, you can:
- Easily join different data sources with read-only access
- Create tombstone records for privacy preservation and anomaly removal
- Create data transformation pipelines that preserve data wrangling efforts and operationalize them in upstream ML operations.
Decouple Models from Apps with Async Inferencing
How do we increase our effectiveness as data scientists without taking on the engineering responsibilities of other teams?
On stage at Transform 2019, Chris Chapo, SVP of Data Analytics at Gap, told a sad story about one of Gap’s early data science projects to create size profiles and determine the range of sizes and distribution necessary to meet demand. Four years ago, the data science team handed the algorithm to a product engineer for implementation in java. Two weeks ago, they realized it had been broken for 3.5 years.
This story reveals that data science teams must be in charge of deploying and managing their models. We can understand, notice when something is going wrong, and debug, whereas app teams will (rightly) treat it like a black box.
Today, data scientists are taught to wrap our models up in a microservice (an API) to query. But traditional synchronous APIs for model deployment pose challenges in terms of security, scaling, and observability for data scientists, who are experts in none of those things.
Async inferencing is a game-changer in model deployment and management. It simplifies the process by publishing instances to an event stream and using an application to make inferences and publish results. By decoupling models from applications, async inferencing allows for easier integration with multiple applications and reduces the burden on data scientists.
Microservice perils still exist, but they are delegated to the event bus that sits in the model. Devops team can manage permissions, access, scaling, rate limiting. Data science can scale and maintain their model processes independently without downtime or version increments for the applications. And application teams can use SDKs in their own programming language to connect.
Monitoring and Triggering to Strengthen Models
With monitoring and explainability, models benefit from application-specific feedback and training beyond initial data sets. Models will decay over time and need to be trained on new data to ensure they are correctly generalized. And more data beats better algorithms; the models being used in production benefit from new columns and features.
Rather than waiting to have the perfect model, deploy and strengthen weak models in production.
After we deploy a model, we should monitor:
- Inference timing to observe how long it takes to make an inference
- Cross-validation scores to cross-validate models over time
- Instance distance from enters to see if new predictions generalized or outscope of training data
- Amount of relevant data to determine if we making good predictions
We can thereby create triggers: alerts and thresholds for MLOps responses in live models — otherwise known as events.
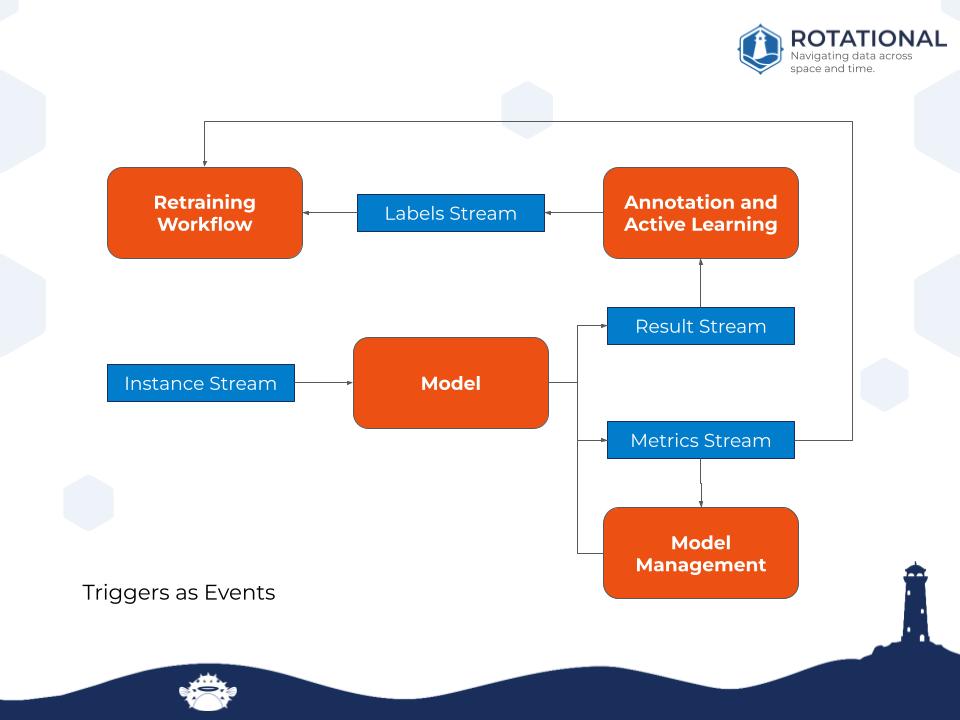
In the proposed workflow above, our instance stream is coming in, and our model is making predictions on them. This model can be routinely cross-validated using that same instance stream and sending out metrics. The metrics can be observed inside of our model management tool.
We can use our results stream for annotation and active learning. If we have human annotators that can like thumbs up or thumbs down different predictions.
And we have a label stream and metrics that allow us to say if we have enough data to retrain our model. We can decay data and retrain data on a new set of data and make sure that we are keeping our models strengthened and engaged with the application over time.
Let’s Tackle the Model Deployment Gap Together
Models get deployed when we design systems that align with our organization’s existing communication structure, as data flows. By leveraging data flows in our analytical processes, we can build models that are more compatible with the rest of the application. And when we do that, more models will get into production (hopefully a lot more than 13%)!
Ready to take the next step? Check out MLOps 201: Data Flows for Real Time Model Inferencing.
Ready to experiment with data streams and change data capture? Check out our data playground and create an Ensign account today!
Photo by Johannes Tandl on Flickr Commons









