

Messy rooms are a hassle. They can leave you sifting through piles of random things until you find what you’re looking for. In the messy world in which we live, the progress of the recommender system and the many approaches one can take in developing one seeks to achieve the goal of the desired choice while eliminating the hassle.
My room can get quite messy. It’s not that I am a messy person, hopefully; but rather there are too many things to organize. I have so many clothes I cannot remember the last time I saw the carpet on the floor of my closet. Things do not seem to stay where I put them, as if they have a mind of their own. The thing I struggle to realize is how all of these things came to be mine. I surely do not need all of these clothes now, but at some point, I must have thought it to be the best choice. With the conception of Amazon and the click of three buttons I can reside within the comfort of my room and whatever I desire will be at my door by tomorrow morning. The irony of it all is that I never have anything to wear. There will always be something new. It is human nature to have desire. Some are innate while others develop as we do. As time flows the only constant is that everything changes. Everything from the thoughts in our minds to the environment around us, nothing remains exactly as it was. With this evolution, desire leads mankind to innovate on all fronts.
The resources those of this era have at our fingertips were beyond imagination two centuries ago. Problems are solved and as with resources comes abundance. It is here that an entirely new issue arises. As everything from technology to appliances is produced by many, for the consumption of all, the question becomes which one. The world as we’ve come to know it is essentially one big messy room. With so many options to choose from, the difficulty derives from the multitude of prospects. This idea is prevalent everywhere and will always remain as desirable things continue to be produced. The skill that is paramount to one’s endeavors to alleviate this difficulty is the narrowing of the choices.
This is the beauty of the recommender system which is the focus of my internship project at Rotational Labs. By inputting information as a functional filter, the output presents narrowed options dependent on said information. With the utilization of tools like these, it will make your world seem a little less messy.
What is SBIR?
SBIR (Small Business Innovation Research) is a program that allows agencies within the government to provide funding to small businesses. SBIR encourages small businesses to participate in government research and development in hopes of a product being commercialized.
SBIR has several topic areas in which businesses can submit proposals in order to receive an opportunity to work with an agency. However, we faced many issues when choosing a topic.
Our dilemmas when finding a topic area
The embedded search engine in the SBIR website is inefficient.
Proposals take a few weeks to write, so we need a topic area whose closing date is farther away.
It is impractical to read through hundreds of topic areas.
At Rotational Labs, if there is a problem, we will find the solution. COO/Founder Rebecca Bilbro recognized this problem and in the blink of an eye, my internship project was birthed.
I would be tasked with building a recommender system that efficiently outputs agency topic areas that modeled Rotational Lab’s mission and values.
Approach 1: Semantic Similarity
Luckily, retrieving the data on the agency topic areas was a breeze. Although the website has changed now, at the time, the SBIR website allowed for easy data collection by providing the data in JSON form.
With the help of Patrick Deziel, I decided my first approach would be a semantic similarity model I retrieved from Hugging Face.
The semantic similarity approach seemed ideal since we already had topic areas that we had approved. Our two approved topic areas were titled Context Aware Data Stream Pre-processor for Time-Sensitive Applications and Signal Cueing in Complex Environments. My idea was to compare other topic areas with ones we had already approved.
def similarity(text, df, n=3):
embeddings = model1.encode(text)
df["Similarity_Score"] = df["Encoded_Text"].apply(lambda x: util.cos_sim(embeddings, x).item())
return df.sort_values(by="Similarity_Score", ascending=False).head(15)
text = sbir_data["Description"].iloc[ideal_ta2]
similarity(text, sbir_data, n = 10)[["TopicTitle", "Similarity_Score", "CloseDate"]]
The topic areas that had higher scores were deemed more semantically similar to the ones we had chosen, therefore being good candidates. I ranked the top 10 similarity scores from highest to lowest and printed the output for both approved topic areas.


As I received into the outputted topic areas, I dug deeper into the full descriptions of them to see whether they truly match Rotational Lab’s mission and values. The results were very hit-or-miss. Some of the topic areas were very far off while the others required a different expertise than Rotational provides. There were few topics that were ideal.
Approach 1b: Semantic Similarity on Summarized Text
Another approach that I thought would be reasonable would be a semantic similarity approach on summarized text. To do this I would select a summarization model from Hugging Face. I thought this might be a better idea since the similarity model could grasp the idea of the text and then compare the similarity of the ideas.
Unfortunately, this approach proved to be even less accurate than the former. All of the inaccuracies resulting from the semantic similarity approach could have been for several reasons.
We were limited to comparing the descriptions to pre-approved topic areas.
We could not properly find topic areas that adhered to Rotational’s mission because we were limited in what we could compare it to.
The summarization model did not allow enough tokens to properly summarize the descriptions of the topic areas, resulting in large chunks of text being cut out the the summarization.
Simply the model I chose for the semantic similarity approach was not ideal for the data I was working with.
Despite, the several flaws associated with this approach, the truth remained that I needed a more accurate approach.
Approach 2: GLiNER
GLiNER (Generalist Model for Named Entity Recognition using Bidirectional Transformer) is a Named Entity Recognition (NER) model that is a practical alternative to other NER options. Unlike other options, GLiNER is not restricted to predefined entities. Usually, other NER models have limited to simple labels such as person, place, organization, etc. GLiNER allows users to select any label they desire.
The idea for this approach was to select labels that adhered to Rotational’s mission and values. For this, I went on Rotational’s About page
labels = ["data", "machine learning", "native computing", "event driven", "data systems", "artificial intelligence"]
Since we are grabbing words and phrases directly from Rotational Labs, we can better eliminate topic areas that have nothing to do with our values. Woohoo to solving problem #2!
So I created a function that takes 3 inputs: a pandas data frame, the selected column of text, and the labels. I also created new columns that show the phrase of text that was associated with the labels.
def top10_withGLiNER(df, column, labels):
model = GLiNER.from_pretrained("urchade/gliner_medium-v2.1")
labels = labels
def predict_entities(text):
entities = model.predict_entities(text, labels)
return [(entity["text"], entity["label"]) for entity in entities]
df['entities'] = df[column].apply(predict_entities)
# Counting number of entities found
df['entity_count'] = df['entities'].apply(len)
df['entity_texts'] = df['entities'].apply(lambda x: [entity[0] for entity in x])
df['entity_labels'] = df['entities'].apply(lambda x: [entity[1] for entity in x])
return df.sort_values(by="entity_count", ascending=False).head(10)
top10_withGLiNER(sbir_data, 'Description2', labels)[["TopicTitle", "entity_count", "CloseDate", "entities"]]
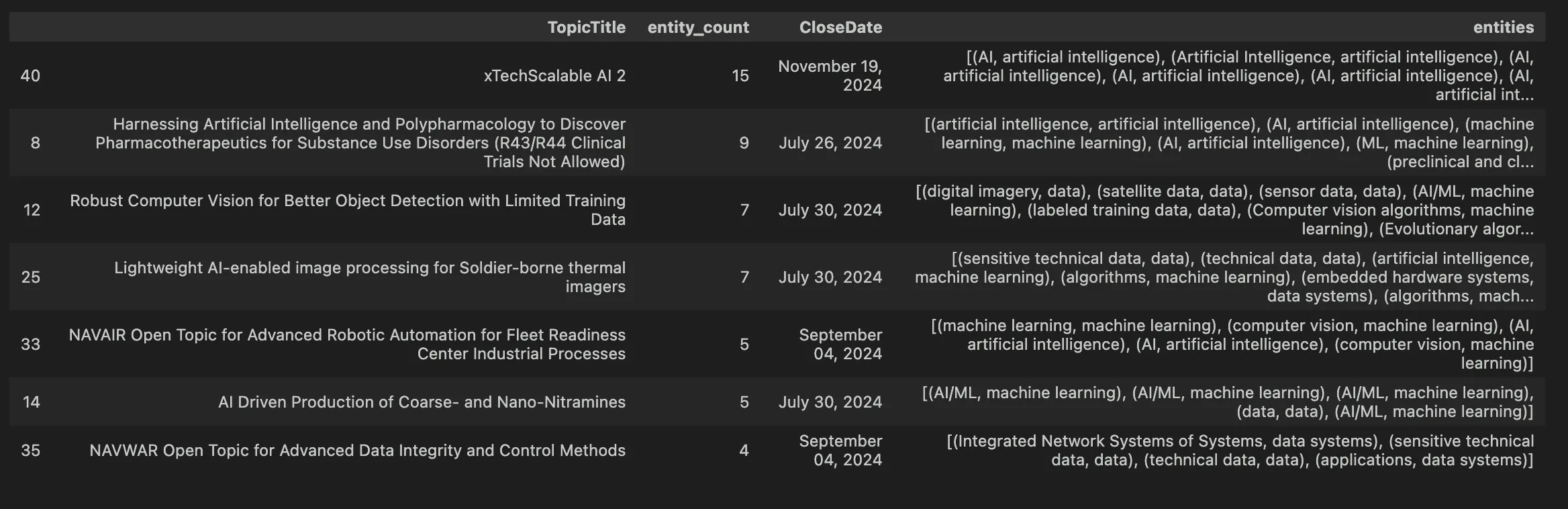
The GLiNER results were somewhat similar to the results of the semantic similarity approach. Despite that, the effectiveness of this approach can still be called into question. A big flaw with the GLiNER approach is that the government’s meanings of the labels may not align with Rotational’s.
Approach 3: Annotating and Training with Prodigy
Although using the GLiNER approach was interesting and enjoyable, it was clear that there were better approaches. With the helpful advice of CEO/Founder Benjamin Bengfort, I was steered to Prodigy.
Prodigy, a product of Explosion, is a data annotation tool that provides a new way to build custom AI systems. Prodigy helps annotate data in several forms. The usages include text classification, named entity recognition, computer vision, and more.
For my SBIR project, annotating and training for a text classification model proved to be the most valuable. The first step in the process was to do a group annotation session with the Rotational Team. For this session, I summarized the topic areas and presented them to the group. A simple yes or no for each topic area did the trick.
% prodigy textcat.manual SBIRAnnotations2 /path/to/firstrealprodigy.jsonl --label Rotational-Oriented
Prodigy is an amazing annotation tool with a user-friendly interface. Prodigy provides easy-to-use recipes that make annotation and training a breeze. Thank you Ines Montani and Matthew Honnibal for creating such an influential and industry-break product. Prodigy will no doubt be a staple in Rotational Lab’s work.
Despite Prodigy’s amazing work on this project, my project had its flaws that even Prodigy could not correct. Although SBIR had hundreds of topic areas. Most get closed quickly, which makes it difficult to retrieve more data. Additionally, they recently underwent website changes which included getting rid of the feature that allows for simple downloading.
Due to this, I could only train using about 60 samples. Although text classification models do not require much training data, it would be better to have more than 60. Regardless, I still trained it.
% prodigy train --textcat-multilabel SBIRAnnotations2 /Users/nnokigbo/Desktop/Rotational-Labs-Internship/SBIR/Prodigy-Use/Annotations-for-training/sbir-model
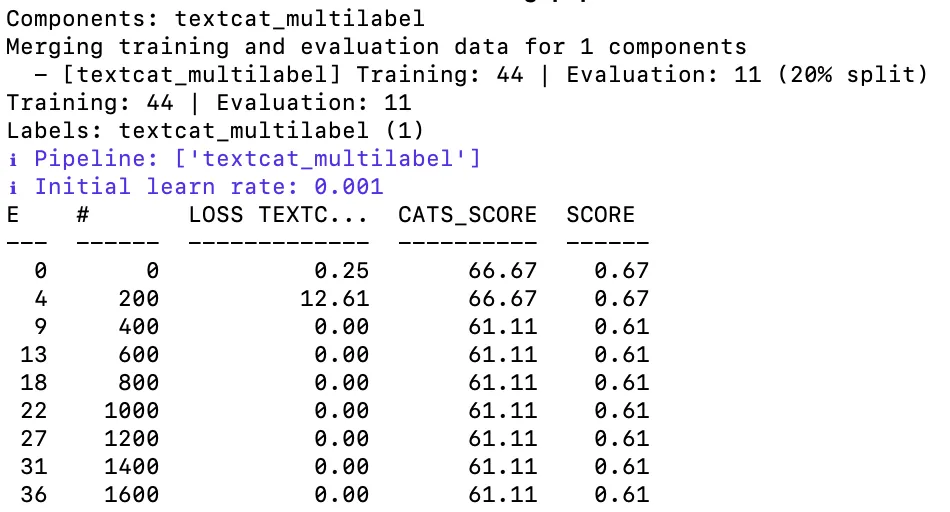
As seen above, a lot can be fixed to make this model more accurate. The loss stabilized at 0.00 meaning that there are signs of overfitting. Also, the score stabilized at 61%. This suggests that as the number of epochs increases, the model’s performance does not improve. The beautiful thing about problems and flaws is that there is always room for improvement.
Ways I Could Improve
I could train more data. I used a small amount of topic areas to train this model.
I could hypertune. It would be nice to experiment with different batch sizes and learning rates to see how the model’s performance would change.
There were very few topic areas that were accepted during the annotations. Maybe if I experimented with synthetic topic areas that were modeled Rotational’s values, the model could have been more accurate
Takeaways
My main lesson while doing this project was a lesson that Rebecca Bilbro highlighted for me – there are only two things in life: the things you know and the things you do not know. There is no third category of things that you are not smart enough to understand.
This lesson spoke to me because I am surrounded by such intelligent people equipped with an abundance of knowledge. There is Patrick with his expertise in fine-tuning - Edwin with his passion for business development - Danielle with her amazing software engineering skills - Prema with her fantastic client work - Benjamin with his dissertation that laid the groundwork for Rotational Labs - Beci with her insane ability to manage everyone’s work and needs - and last but most certainly not least, Rebecca with her brilliant technical mind and unbelievable ability to make everyone feel special.
Being around incredible people shows me that, just like them, I have valuable capabilities that can get me and the relationships I hold far in life.
With the clutter created as a byproduct of abundance through the reality of options, it is easy to get overwhelmed. There are ways to approach the clutter that are far more efficient than sifting through the pile of clothes on the floor. The solution is to construct a system that works for you. That can be difficult, as it is not quite that simple. Trial and error is a must, while setbacks give you the necessary momentum to get you farther than you’ve imagined. The name of the game is experience. Making the most out of opportunities is vital, as a certainty in which I live is that if you continually put forth full effort you will consistently be a better version of yourself tomorrow. Much is the same with my recommender system project. Taking new approaches provided altered perspectives that were immeasurable in value when reflecting on the progression of my system.
Image by user15285612 on Freepik



