The LLMs boom has made differentiating text written by a person vs. generated by AI a highly desired technology. In this post, I’ll attempt to build an AI text detector from scratch!
Previous Work
Since ChatGPT was released there’s been a lot of interest in being able to distinguish human written text from text generated by large language models (LLMs), primarily among teachers and educators. So far there has been limited success actually implementing these tools. OpenAI themselves released an AI classifier which was pulled only a few months later due to low accuracy. On their website they claim:
Our classifier is not fully reliable. In our evaluations on a “challenge set” of English texts, our classifier correctly identifies 26% of AI-written text (true positives) as “likely AI-written,” while incorrectly labeling human-written text as AI-written 9% of the time (false positives).
The currently most successful AI text detector is GPTZero which utilizes a deep learning model in addition to several heuristic methods such as analyzing the writing consistency and an internet text search.
Approaching the Problem
One of the reasons why generalized AI text detection is so difficult is that the domain is gigantic. GPTZero required massive text corpora from the internet in addition to synthetic data sets they generated themselves to train their deep learning model. If you’re looking into building a proprietary AI detection model, identifying a specific use case (e.g. rating student essays) in a domain you have specific knowledge and expertise in will increase your chances of success.
But what if you don’t have the data to build a robust machine learning model? Are there more cost-effective approaches to AI text detection?
Some recent research suggests that there are particular signals in AI-generated text that can be detected. For example, a Stanford paper published in April identified a word frequency shift in scientific papers dating back to when ChatGPT was released. Words such as “pivotal”, “intricate”, “realm”, and “showcasing” are reportedly used more often by LLMs than humans. Unfortunately, using these sorts of words to produce rule-based solutions (e.g. filters) to detect AI text have a clear weakness — human language is highly contextual (in domains like gaming, people use the word “realm” all the time!). Human language is also always changing — new words enter our collective vocabularies, or become more or less common. This means that machine learning is likely required for detecting AI generated text.
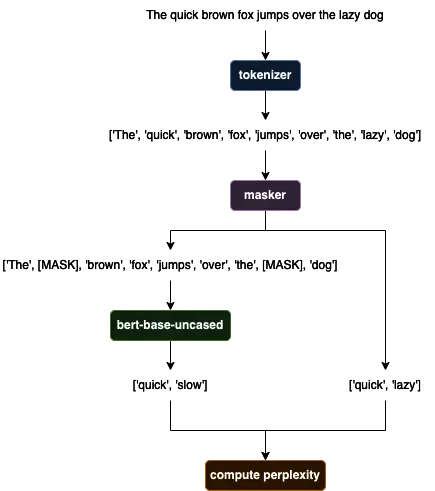
I wanted to try building a text detector to take advantage of this signal. My approach was to mask out a certain percentage of tokens in the text, use a generative model to predict the tokens that were masked, and compare the predictions to the original tokens. In theory, human-written text is more varied than LLM-generated text so the more accurate the predictions were, the more likely it is that the text is AI-generated. This approach is very similar to the “perplexity” measure used by GPTZero.
The Code
The tricky part to the implementation is selecting the tokens to mask and stitching the sequence back together for the LLM. One thing I quickly realized was the mask selection will greatly impact the perplexity score (e.g. prepositions like “a” and “the” are easier to predict than proper nouns). My implementation filters out obvious stopwords before token selection. Because the masking is random, a better approach might be to take an average of multiple masking rounds or use a shifting window so the generative model uses local context for its predictions.
import nltk
import random
from transformers import pipeline
from nltk.tokenize import word_tokenize
class AIOrHumanScorer():
"""
Score text that may have been produced by a generative model.
"""
def __init__(self, model: object, mask_filler="bert-base-uncased"):
self.model = model
self.mask_fill = pipeline("fill-mask", model=mask_filler)
self.labels = ["human", "auto"]
nltk.download("punkt")
nltk.download("stopwords")
self.stop_words = set(nltk.corpus.stopwords.words("english"))
def _mask_fill(self, text: str, mask_ratio=0.15, max_tokens=512, random_state=42) -> tuple:
"""
This function computes a mask fill score for a text sample. This score is
computed by randomly masking words in the text and checking how well a mask
fill model can predict the masked words. Returns a tuple of
(true_tokens, pred_tokens).
"""
# Truncate to ensure the text is within the token limit
tokens = word_tokenize(text)[:max_tokens]
# Randomly select words to mask, ignoring stopwords
random.seed(random_state)
candidates = [(i, t) for i, t in enumerate(tokens) if t.lower() not in self.stop_words and t.isalnum() and len(t.strip()) > 1]
if len(candidates) == 0:
raise ValueError("No valid tokens after stopword removal.")
n_mask = int(len(candidates) * mask_ratio)
if n_mask == 0:
n_mask = 1
# Mask the target words
targets = sorted(random.sample(candidates, n_mask), key=lambda x: x[0])
masked_tokens = [t[1] for t in targets]
masked_text = ''
for i, token in enumerate(tokens):
if len(targets) > 0 and token == targets[0][1]:
masked_text += '[MASK] '
targets.pop(0)
else:
masked_text += token + ' '
# Get the mask fill predictions
fill_preds = [f['token_str'] for f in self.mask_fill(masked_text, tokenizer_kwargs={'truncation': True})[0]]
return masked_tokens, fill_preds
def score(self, text: str, mask_fill_threshold=0.4) -> float:
"""
Return a dict of scores that represents how likely the text was produced by a
generative model.
"""
# Compute the mask fill score
true_tokens, pred_tokens = self._mask_fill(text)
return sum([1 for t, p in zip(true_tokens, pred_tokens) if t == p]) / len(true_tokens)
This code uses the bert-base-uncased model from HuggingFace. Since different models will produce different results, it would be interesting to try different models to determine which class of models generated the text (e.g. LLaMA, Mistral, GPT, etc.).
Evaluation
To test the performance of the approach, I used a dataset of labeled human-written and AI-written essays from kaggle. Since the score method outputs a value in the range [0, 1], I did some quick parameter tuning to select the binary classification threshold that maximizes the area under the ROC curve (AUC).
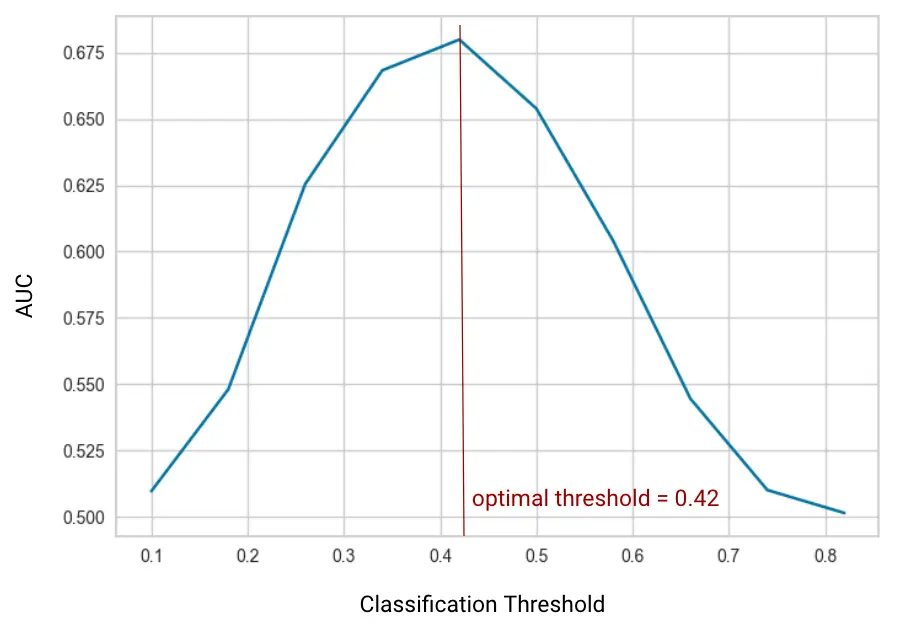
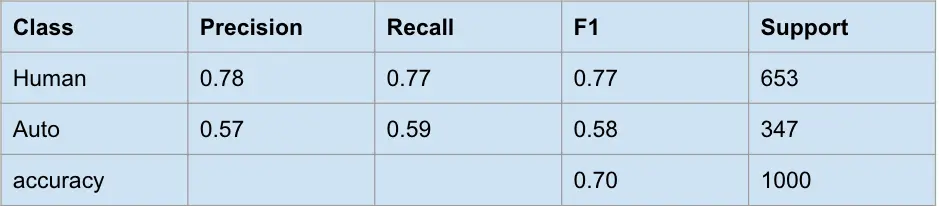
The results against the evaluation set show that the accuracy is a bit better than random guessing, but I certainly wouldn’t stake any academic integrity on it!
Future Work
In order to combat the AI-ification of the internet we will need to have models and tools to detect AI-generated context. Using heuristics like perplexity and writing consistency seem to have some promise but relying on an all-in-one solution is unlikely to sufficient. In the future we will need the ability to develop domain-specific models that are tuned to particular detection tasks. These models will also need to be flexible and capable of evolving, because natural language is highly contextual, and continuously changing over time.
Bonus
I did not use AI in the creation of this post - but for fun here’s what GPTZero says.
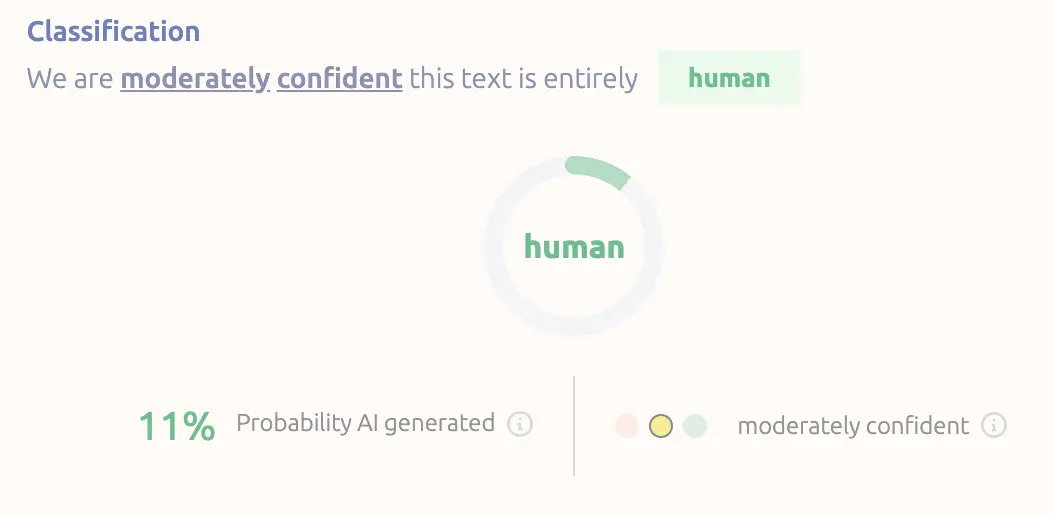
Photo by Steve Johnson on Unsplash