

In our first installment on how to implement the famous Raft algorithm, we introduced the log: an ordered sequence of operations that serves as the core data structure for distributed consensus. In this second part, we’ll demonstrate the beating heart of Raft, which is log replication.
If you’re following along at home, don’t forget to check out this handy Github repository containing a Raft implementation done as an exercise for Rotational’s internal Distributed Systems Bootcamp. Be sure to check out the first post in the series too!
The Raft RPCs
Raft can be implemented in three remote procedure calls (RPCs):
service Raft {
rpc AppendEntries(stream AppendEntriesRequest) returns (AppendEntriesReply) {};
rpc RequestVote(VoteRequest) returns (VoteReply) {};
rpc Submit(SubmitRequest) returns (SubmitReply) {};
}
In the next post, we’ll explore RequestVote and Submit, so in this post we’ll focus on the AppendEntries RPC, which expects a stream of AppendEntriesRequest (using unary streaming to enhance performance) and returns an AppendEntriesReply. As we’ll see in the next section, these messages enable Raft’s core state replication functionality.
Log Replication
Log replication refers to the way we keep our peers’ state synchronized in a distributed system. In Raft, we can implement log replication using an RPC called AppendEntries. The Raft paper delineates five steps that must be executed within the AppendEntries RPC to ensure that log replication is safe and correct, meaning we can algorithmically prove that all peers will execute all of the same commands in the same order every time.
In the next few sections, we will spend some time going over each of the 5 steps of the log replication process and their purpose. For a full implementation of the log replication function at work, check out the AppendEntries function from the example code.
AppendEntries Steps
First, let’s examine the RPC definitions for the AppendEntriesRequest and AppendEntriesReply messages.
When a presumptive leader (which we’ll call Alpha) wants to propose a new log entry to its peers (let’s call them Beta and Gamma), it will send out an AppendEntriesRequest. In our first post in this series, we explained that a Term describes a leader’s continuous duration during the consensus process. Alpha will include its perspective of the term in this AppendEntriesRequest:
Note: some fields omitted for brevity.
message AppendEntriesRequest {
string id = 1; // The uuid of the Raft node sending the request.
int32 term = 2; // The term from the requester's perspective.
int32 prevLogIndex = 4; // Index of entry immediately preceding new ones.
int32 prevLogTerm = 5; // The term of the prevLogIndex entry.
repeated Entry entries = 6; // New ops to append.
int32 leaderCommit = 7; // The leader’s commitIndex.
}
When Beta and Gamma receive Alpha’s request, they’ll respond with an AppendEntriesReply:
message AppendEntriesReply {
string id = 1; // The uuid of the Raft node sending the reply.
int32 term = 2; // The term from the respondent's perspective.
bool success = 3; // True if consensus
}
1. Reply false if term < currentTerm
For AppendEntries to work correctly, we must ensure that no new log entries are appended if Alpha’s term has been superseded by a newer term. Since terms are incremented when a new leader comes to power, if a server received an AppendEntriesRequest from a peer with a term less than its own, we can assume that this peer is out of date, and is not the correct leader. This step handles the problem of stale leaders, which can happen if network delays cause an AppendEntriesRequest to be late, at which point a new leader can be elected, rendering the request out-of-date.
So, when Beta and Gamma receive an AppendEntriesRequest, they must first ensure that Alpha’s term is not less than their own.
2. Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm
This step handles the problem of Log ordering. Consider the case where we have three sequential AppendEntriesRequests sent from Alpha to Beta and Gamma. Because of network delays, these may end up arriving at Gamma out of order, causing incorrect log ordering in Gamma’s log.
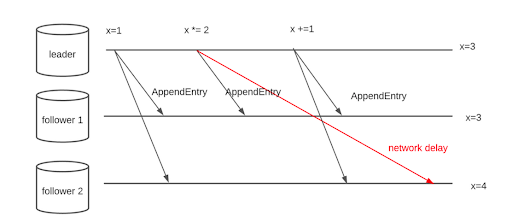
To prevent this, Raft uses two fields in the AppendEntriesRequest containing the previous request the leader issued. In this way we can ensure that each follower has received the previous command before committing a new one. This also provides two emergent properties:
- If two entries in different logs have the same index and term, then they store the same command
- If two entries in different logs have the same index and term, then the logs are identical in all preceding entries
Together these are called the Log Matching Property, and they are very important to Raft’s safety and fault tolerance guarantees.
3. If an existing entry conflicts with a new one, delete the existing entry and all that follow it
In the case of things like network partitions (let’s say one peer loses contact with the rest of the peer group, failing to sync with them, but is still receiving client requests), we may run into a situation where a server’s log is out of sync with the rest of the cluster.
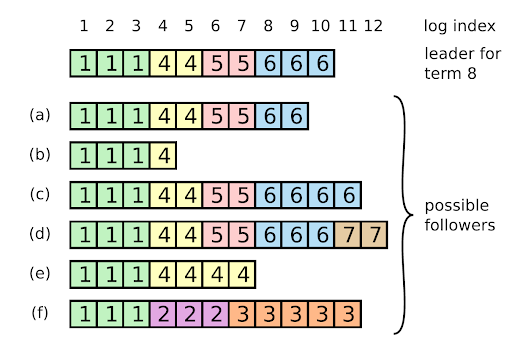
Algorithmically speaking, Beta will know it has identified a potential problem if Alpha’s AppendEntriesRequest refers to a previous index for which Beta already has an entry with a term older than Alpha’s term.
4. Append any new entries not already in the log.
Following up from the previous step, if Beta finds any inconsistencies, it will overwrite its log using the information included in Alpha’s AppendEntriesRequest.
5. If leaderCommit > commitIndex, fast forward
Finally, if Beta sees that Alpha’s highest committed entry (leaderCommit) is greater than its own local highest committed entry (commitIndex), Beta knows it needs to increase its local index position. If Beta is still awaiting additional entries (e.g. from an AppendEntriesRequest it has received out of order), it will update its local commitIndex to be equal to the current length of the log. Otherwise, if Alpha’s AppendEntriesRequest contains all of the latest entries Beta needs to be in sync, Beta will update its local commitIndex to be the same as Alpha’s.
Next Time…
In the third and final installment we’ll finally be taking a look at how Raft handles leader elections. If you missed the first part of our Raft series you can find part 1 here.








