2023 was the year of large language models (LLMs) due to services like ChatGPT and Stable Diffusion gaining mainstream attention. In this series, learn about the architecture behind LLMs and how to build your own custom LLM!
Note: This tutorial requires Python >= 3.9
ChatGPT has an API, why do I need my own LLM?
We’ve come a long way since Microsoft’s Clippy.
ChatGPT is arguably the most advanced chatbot ever created, and the range of tasks it can perform on behalf of the user is impressive. However, there are aspects which make it risky for organizations to rely on as a permanent solution.
- It’s controlled by a third party who can disable features or change its functionality and API at any time.
- It’s a SaaS, so your users might experience latency issues that you can’t address directly.
- The per-request cost model can get expensive.
- It may require a significant amount of prompt engineering to get right (and sometimes it’s just wrong).
- It introduces the risk of prompt injection by malicious users.
There are certainly disadvantages to building your own LLM from scratch. LLMs notoriously take a long time to train, you have to figure out how to collect enough data for training and pay for compute time on the cloud.
But guess what, you don’t have to start from scratch.
Transfer learning is an efficient and practical way to fine tune an existing open source language model and produce a custom LLM. If your organization has specific data tenancy needs or requires a model with knowledge about a more specific domain or task, it may be worth it to build your own LLM!
Creating a Movie Reviews Corpus
In order to train or fine-tune an LLM, you need a training corpus. Obtaining a representative corpus is sneakily the most difficult part of modeling text.
If you’re aiming to build intellectual property, this is where you’d want to bring in your in-house document cache — news feeds, blog posts, emails, documents, Sharepoints, Powerpoints, all the points. Make sure you budget enough time for this step; it takes longer than you think.
For this post, we’ll save time by using a pre-curated dataset that contains 100k IMDB movie reviews that was initially created for sentiment analysis. We will fine-tune an existing open source model using this specialized corpus, and then we will test it to see if it performs better than the base GPT, BERT, or RoBERTa models on NLP tasks involving user movie reviews.
Ingesting the Data
A corpus is a collection of documents. In our example, a document is a single movie review. In Ensign, creating a corpus of documents is equivalent to publishing a series of events to a topic. Before ingesting anything, you need to create an Ensign project.
- Create an Ensign account at rotational.app.
- Create a new Ensign project (e.g. movie-assistant).
- Create a topic within the new project (e.g. movie-reviews-text).
- Create an API key with publish and subscribe permissions (don’t forget to download it).
The next step is to install the package dependencies. datasets is a helper to download datasets from HuggingFace and pyensign is the Ensign Python SDK.
$ pip install datasets
$ pip install "pyensign[ml]"
Next we’ll write some Python code to stream the documents into Ensign. Each document will be a separate event, and we’ll include the sentiment as well as the split labels in case we need them later. The code below is meant to be run within a Python notebook like Jupyter. Remember to substitute the Client ID and Client Secret from your API key!
import json
from datasets import load_dataset
from pyensign.events import Event
from pyensign.ensign import Ensign
# Helper function to write events to the topic store
def write_events(split):
for record in load_dataset("imdb", split=split, streaming=True):
data = {
"text": record["text"],
"label": record["label"],
"split": split,
}
yield Event(
json.dumps(data).encode("utf-8"),
mimetype="application/json",
schema_name="reviews-raw",
schema_version="0.1.0"
)
ensign = Ensign(
client_id=<your client ID>,
client_secret=<your client secret>
)
TEXT_TOPIC = "movie-reviews-text"
for event in write_events("train"):
await ensign.publish(TEXT_TOPIC, event)
for event in write_events("test"):
await ensign.publish(TEXT_TOPIC, event)
for event in write_events("unsupervised"):
await ensign.publish(TEXT_TOPIC, event)
After running the code, you should see 100k events published to Ensign on the topic dashboard. Another way to confirm that the ingestion worked is to run a query and convert the events into a DataFrame.
from pyensign.ml.dataframe import DataFrame
cursor = await ensign.query("SELECT * FROM movie-reviews-text")
df = await DataFrame.from_events(cursor)
df.head()
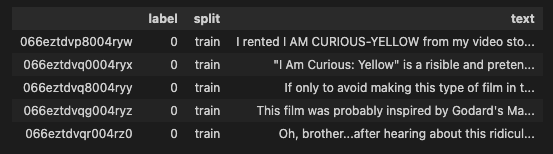
The DataFrame should contain the three splits in the dataset (train, test, unsupervised).
print("train", len(df[df["split"] == "train"]))
print("test", len(df[df["split"] == "test"]))
print("unsupervised", len(df[df["split"] == "unsupervised"]))
train 25000
test 25000
unsupervised 50000
To be continued…
Now that you have a custom text corpus in Ensign, in the next module you will train an LLM using semi-supervised learning!
Image generated by DALL-E